
MATLAB、Python、Scilab、Julia比較ページはこちら
https://www.simulationroom999.com/blog/comparison-of-matlab-python-scilab/

はじめに

の、
MATLAB,Python,Scilab,Julia比較 第4章 その26【シグモイドによる決定境界安定化⑥】
を書き直したもの。
活性化関数をシグモイド関数にした形式ニューロンをJuliaで実現
【再掲】シグモイド関数
差し替えるシグモイド関数の数式と波形は以下になる。
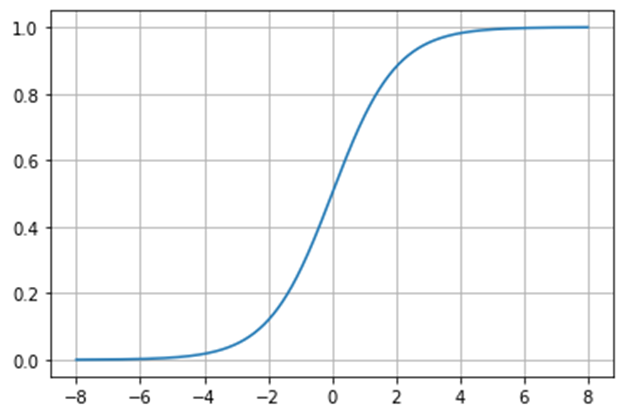
\(
\displaystyle\varsigma=\frac{1}{1+e^{-ax}}=\frac{tanh(ax/2)+1}{2}
\)
これを活性化関数とした形式ニューロンをJuliaで実現する。
Juliaコード
Juliaコードは以下
function sigmoid(x)
return 1.0 ./ (1.0 + exp.(-x))
end
using PyPlot
function NeuronalBruteForceLearningHeaviside()
# データセットの入力
X = [0 0; 0 1; 1 0; 1 1]
# データセットの出力
Y = [0; 0; 0; 1]
# パラメータの初期値
W = zeros(2, 1) # 重み
b = 0 # バイアス
num_epochs = 10000 # 学習のエポック数
learning_rate = 0.1 # 学習率
min_loss = Inf
learning_range = 4
n = length(Y)
# 重みの総当たり計算
best_w1, best_w2, best_b = 0, 0, 0
for w1 = -learning_range:learning_rate:learning_range
for w2 = -learning_range:learning_rate:learning_range
for b = -learning_range:learning_rate:learning_range
# フォワードプロパゲーション
Z = X * [w1; w2] .+ b # 重みとバイアスを使用して予測値を計算
A = sigmoid.(Z) # シグモイド活性化関数を適用
# 損失の計算
loss = 1/n * sum((A - Y).^2) # 平均二乗誤差
# 最小損失の更新
if loss < min_loss
min_loss = loss
best_w1 = w1
best_w2 = w2
best_b = b
end
end
end
# ログの表示
println("loss: $min_loss")
println("weight: w1 = $best_w1, w2 = $best_w2")
println("bias: b = $best_b")
end
# 最小コストの重みを更新
W = [best_w1; best_w2]
b = best_b
# 学習結果の表示
println("learning completed")
println("weight: w1 = $(W[1]), w2 = $(W[2])")
println("bias: b = $b")
# 出力結果確認
println("X=$(X)")
result = sigmoid.(X * [W[1]; W[2]] .+ b)
println("hatY=$(result)")
# 決定境界線のプロット
x1 = range(-0.5, 1.5, length=100) # x1の値の範囲
x2 = -(W[1] * x1 .+ b) / W[2] # x2の計算
scatter(X[Y .== 0, 1], X[Y .== 0, 2], color="r", marker="o", label="Class 0")
scatter(X[Y .== 1, 1], X[Y .== 1, 2], color="b", marker="o", label="Class 1")
plot(x1, x2, color="k", linewidth=2)
xlim([-0.5, 1.5])
ylim([-0.5, 1.5])
# グラフの装飾
title("Decision Boundary")
xlabel("x1")
ylabel("x2")
legend(["Class 0", "Class 1", "Decision Boundary"])
grid(true)
show()
end
NeuronalBruteForceLearningHeaviside()処理結果
処理結果は以下
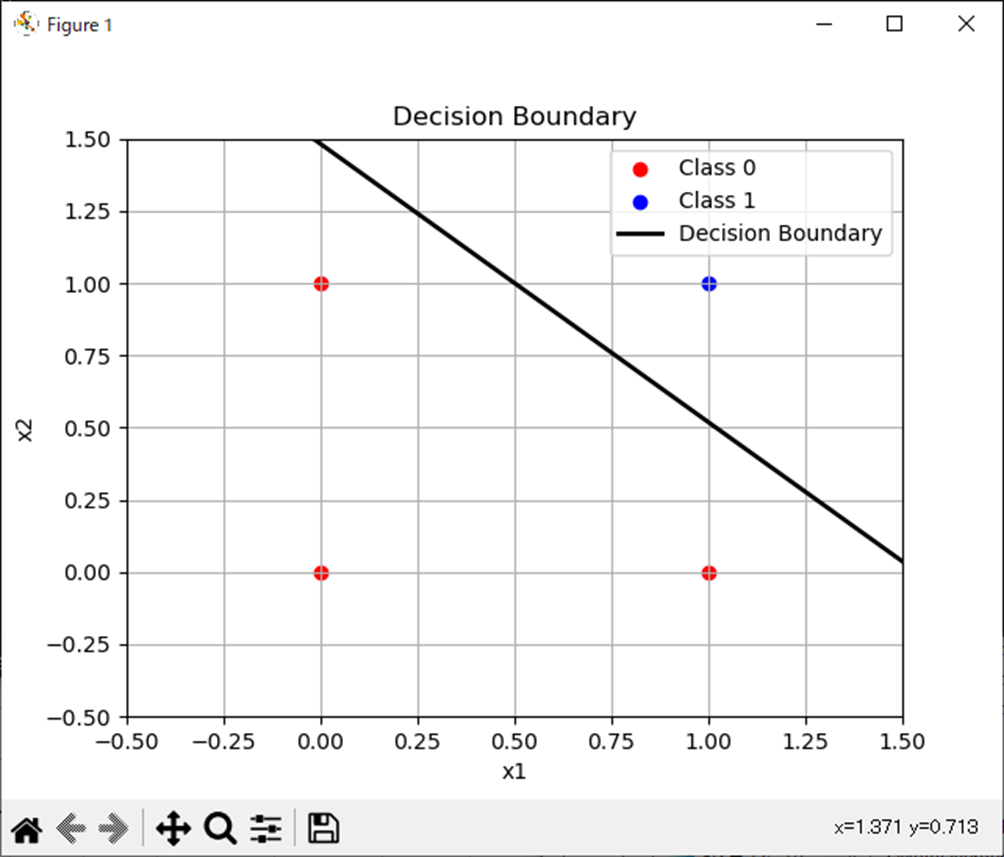
weight: w1 = 2.6, w2 = 2.7
bias: b = -4.0
X=[0 0; 0 1; 1 0; 1 1]
hatY=[0.01798620996209156, 0.21416501695744142, 0.19781611144141825, 0.7858349830425586]まとめ
- 活性化関数をシグモイド関数にした形式ニューロンをJuliaで実現。
- 結果はカスタムヘヴィサイドの時と一緒。
MATLAB、Python、Scilab、Julia比較ページはこちら
Pythonで動かして学ぶ!あたらしい線形代数の教科書

Amazon.co.jp: Pythonで動かして学ぶ!あたらしい線形代数の教科書 eBook : かくあき: Kindleストア
Amazon.co.jp: Pythonで動かして学ぶ!あたらしい線形代数の教科書 eBook : かくあき: Kindleストア
amzn.to
ゼロから作るDeep Learning ―Pythonで学ぶディープラーニングの理論と実装

ゼロから作るDeep Learning ―Pythonで学ぶディープラーニングの理論と実装 | 斎藤康毅 |本 | 通販 | Amazon
Amazonで斎藤康毅のゼロから作るDeep Learning ―Pythonで学ぶディープラーニングの理論と実装。アマゾンならポイント還元本が多数。斎藤康毅作品ほか、お急ぎ便対象商品は当日お届けも可能。またゼロから作るDeep Learn...
amzn.to
ゼロからはじめるPID制御

ゼロからはじめるPID制御 | 熊谷 英樹 |本 | 通販 | Amazon
Amazonで熊谷 英樹のゼロからはじめるPID制御。アマゾンならポイント還元本が多数。熊谷 英樹作品ほか、お急ぎ便対象商品は当日お届けも可能。またゼロからはじめるPID制御もアマゾン配送商品なら通常配送無料。
amzn.to
OpenCVによる画像処理入門

OpenCVによる画像処理入門 改訂第3版 (KS情報科学専門書) | 小枝 正直, 上田 悦子, 中村 恭之 |本 | 通販 | Amazon
Amazonで小枝 正直, 上田 悦子, 中村 恭之のOpenCVによる画像処理入門 改訂第3版 (KS情報科学専門書)。アマゾンならポイント還元本が多数。小枝 正直, 上田 悦子, 中村 恭之作品ほか、お急ぎ便対象商品は当日お届けも可能。...
amzn.to
恋する統計学[回帰分析入門(多変量解析1)] 恋する統計学[記述統計入門]

恋する統計学[回帰分析入門(多変量解析1)] 恋する統計学[記述統計入門] | 金城俊哉 | 数学 | Kindleストア | Amazon
Amazonで金城俊哉の恋する統計学 恋する統計学。アマゾンならポイント還元本が多数。一度購入いただいた電子書籍は、KindleおよびFire端末、スマートフォンやタブレットなど、様々な端末でもお楽しみいただけます。
amzn.to
Pythonによる制御工学入門

Amazon.co.jp: Pythonによる制御工学入門 (改訂2版) eBook : 南裕樹: Kindleストア
Amazon.co.jp: Pythonによる制御工学入門 (改訂2版) eBook : 南裕樹: Kindleストア
amzn.to
理工系のための数学入門 ―微分方程式・ラプラス変換・フーリエ解析

理工系のための数学入門 ―微分方程式・ラプラス変換・フーリエ解析― | 一色秀夫, 塩川高雄 | 数学 | Kindleストア | Amazon
Amazonで一色秀夫, 塩川高雄の理工系のための数学入門 ―微分方程式・ラプラス変換・フーリエ解析―。アマゾンならポイント還元本が多数。一度購入いただいた電子書籍は、KindleおよびFire端末、スマートフォンやタブレットなど、様々な端...
amzn.to


コメント