
MATLAB、Python、Scilab、Julia比較ページはこちら
https://www.simulationroom999.com/blog/comparison-of-matlab-python-scilab/

はじめに

の、
MATLAB,Python,Scilab,Julia比較 第4章 その107【最適化アルゴリズム⑥】
MATLAB,Python,Scilab,Julia比較 第4章 その108【最適化アルゴリズム⑦】
を書き直したもの。
Adamに至るまでの最適化アルゴリズムの系譜の説明をした。
今回は全体としての依存関係についての説明と、
Adamをプログラムで実現するための準備をする。
最適化アルゴリズムいろいろ【再掲】
まずは説明予定の最適化アルゴリズムを再掲。
- AdaGrad(済)
- RMSprop(Root Mean Square Propagation)(済)
- AdaDelta(済)
- Adam(Adaptive Moment Estimation)(済)
というわけで当初の予定は説明終了。
各最適化アルゴリズムの依存関係
各種最適化アルゴリズムの説明は終わったから
恒例のプログラム化になるのだが、
その前に、これまでの最適化アルゴリズムの依存関係を見てみる。
(何かの拡張がどれとか、あれとそれがくっついてこれになったとかあったので・・・。)
図で示すとこんな感じになる。
括弧内の数値は登場した年とか活躍していいた期間を表している。
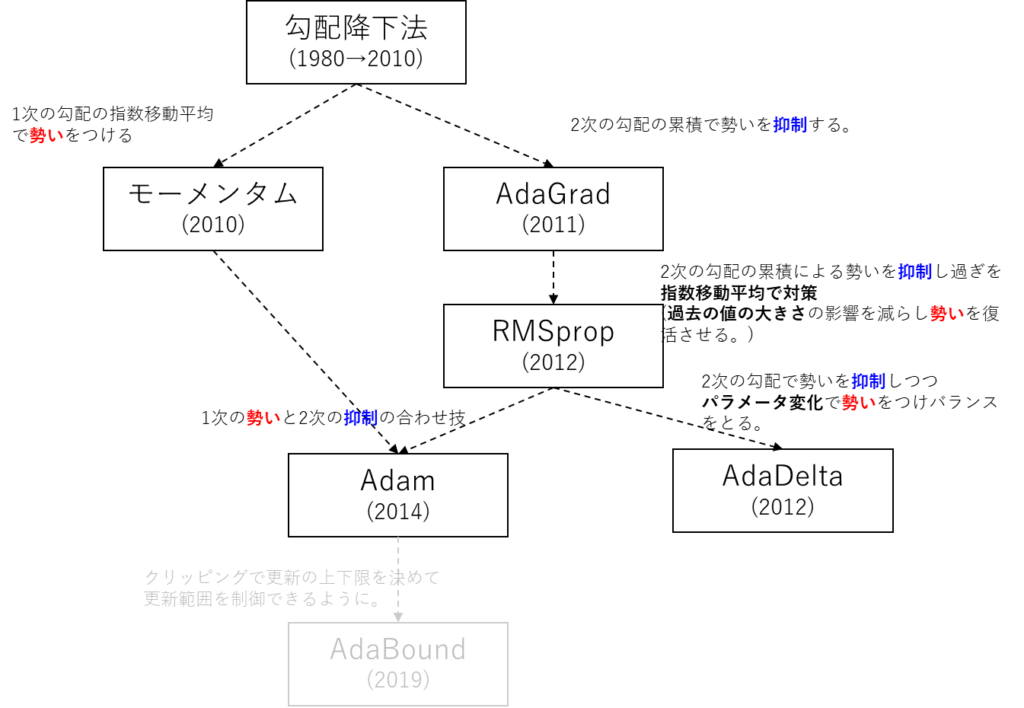
全体を見渡せると分かり易い気がしてくる。
基本的には1次の勾配で勢いをつけて、2次の勾配で抑制って感じになる。
その両方を取り込んだのがAdamってことになる。
Adamのあとも、うっすらとAdaBoundっての記載している。
今回は取り扱わなかったが、AdaBoundはAdamの拡張系の最適化アルゴリズム。
差分としてはクリッピングで学習率の範囲を指定できる点。
Adamでも学習率が下がりすぎて更新が効かなくなるのをクリッピングで更新し続けられるような仕掛けが追加されてる。
Adamの更新式【再掲】
ここで各最適化アルゴリズムの説明は終了。
プログラム化に向けての準備をする。
まずはAdamの更新式を再掲しておこう。
\(
\begin{eqnarray}
m_{t+1}&=&\beta_1 m_{t-1}+(1-\beta_1)\nabla J(\theta_t)\\
v_{t+1}&=&\beta_2 v_{t-1}+(1-\beta_2)(\nabla J(\theta_t))^2\\
\displaystyle\hat{m}_{t+1}&=&\frac{m_{t+1}}{1-\beta_1}\\
\displaystyle\hat{v}_{t+1}&=&\frac{v_{t+1}}{1-\beta_2}\\
\displaystyle\theta_{t+1}&=&\theta_t-\frac{\alpha}{\sqrt{\hat{v}_{t+1}}+\epsilon}\\
m_t&:&1次のモーメント\\
v_t&:&2次のモーメント\\
\hat{m}_t,\hat{v}_t&:&バイアス補正項\\
\beta_1,\beta_2&:&指数移動平均係数(\beta_1=0.9,\beta_2=0.999)
\end{eqnarray}
\)
プログラムフロー
プログラムの流れはモーメンタムの時と一緒になる。
モーメンタムの更新式の部分をAdamの更新式に置き換えるだけ。
よって、プログラムのフローはこれになる。
- シグモイド関数の定義
- シグモイド関数の導関数の定義
- データの準備
- ネットワークの構築
- 重みとバイアスの初期化
- モーメンタム項の初期化
- 学習(4000エポック)
- 順伝播
- 誤差計算(平均二乗誤差)
- 逆伝播
- パラメータの更新(Adam)
- 決定境界線の表示
パイパーパラメータについて
あと、学習率の設定だが、0.001とかなり小さい値を設定する。
これはAdamを使用する際の推奨値みたいなもので、
変更しても構わないのだが、今回はこの推奨値で行く。
その結果として、学習の収束までのエポック数を増やす必要がある。
だいたい20000エポックまで増やす予定。
Adam自体は学習率をモーメンタムのときのように0.5にすると一瞬で終わる
が、モーメンタムでは出てこなかったような結果が拾えることがある。
今回はそれを見ることの方をメインとしたい。
つまり、学習速度が遅くなるけど、Adamならではの最適解を確認したいってことになる。。
よって、学習の収束までの速度の比較は行わない予定。
まとめ
- 各最適化アルゴリズムの依存関係を記載。
- 1次の勾配で勢いをつけて、2次の勾配で抑制するというのが全体を通しての共通点。
- Adamの更新式を実現するためのプログラムフローを記載。
- 学習率は0.001とかなり小さめの値に設定。
- これにより収束は遅くなる。
- かわりに特殊な最適解が得られるのでそれを確認する。
MATLAB、Python、Scilab、Julia比較ページはこちら
Pythonで動かして学ぶ!あたらしい線形代数の教科書

ゼロから作るDeep Learning ―Pythonで学ぶディープラーニングの理論と実装

ゼロからはじめるPID制御

OpenCVによる画像処理入門

恋する統計学[回帰分析入門(多変量解析1)] 恋する統計学[記述統計入門]

Pythonによる制御工学入門

理工系のための数学入門 ―微分方程式・ラプラス変換・フーリエ解析



コメント