
はじめに
2020年3月14日に実施された日本ディープラーニング協会ジェネラリスト検定(通称:G検定)に無事合格。
よって、どのように勉強したのかとか感想を記載する。
さらに実際の出題数、難易度等をシラバス単位で解説。
シラバス単位の出題数は、試験当日に走り書きした雑なメモから思い出しながら書き出したので、おおよその値となる。
今後のG検定受験者の役に立てれば幸い。
一応、試験前に作ったノートも貼っている。
使用禁止されているが、カンペ(カンニングペーパー、チートシート)にもならなくはない・・・。
2020#2,#3,2021#1,#2,#3および2023年以降の情報も随時追記している。
過去問っぽい問題集も設置しているので、気軽に解いていってください。(ひたすら過去問ふぅ問題で鍛錬する所)
結論を先に書いてしまうと、おおよそ以下。
- 事前調査。
- 問題数とか1問あたりに使って良い時間
- シラバス。
- 問題傾向。
- テキスト、問題集、AI白書等による知識インプット。
- 問題集問いて満遍なく慣らす。
- 動画見て大雑把に漏れ抜けを拾っていく。
- 上記を元にカンペを作る。
- 当日にそのカンペを使う使わないはお任せ。どちらかというとカンペを作る過程に意味がある。
尚、文字数/画像数が多いためかページが重くなったので5ページに分割しました。
類似の検定
ディープラーニングでなく、データサイエンスの検定としてデータサイエンティスト検定というものがある。
それについても、記事にしているので興味ある方はどうぞ。

あと、AI実装検定B級の記事も

そしてAI実装検定A級

解説動画
試験的に音声合成ソフトウェアVOICEVOXを使用したG検定解説動画を作成。
本動画群に対して合格者の方からお礼メールいただきました。
知識ゼロの状態から頑張って勉強して対策されたようです。
初心者にもとても分かりやすいとご評価いただき誠にありがたいことです。
下の方に設置している過去問っぽい問題集もご利用いただいたようです。
さらに、
Youtubeチャンネル側に、かなりありがたいコメントを頂いています。
(大学生の方のようです。ご本人の自己評価は低めな感じでしたが、ここまで状況の分析と表現ができる方は結構優秀な気はします)
勉強時間20時間
難易度-SyudyAIと同等orやや上?(数問いやらしい長文の問題あり)
問題数-191問 カンペ参照しながらだと時間ぎりぎり最新の問題はそんなにでなかった
ChatGPTとAIイラスト生成にかかわる問題あり。
ChatGPTは使われてるモデルの名前?(忘れた・・・)
AIイラスト生成は(著作権にかかわる問題)簡単な問題が少なかった印象(深く意味知らなくても解ける問題)
法律系がやっぱ鬼門、個人情報やデータの営業秘密についてわかったつもりになるのが一番危険!
浅い理解だと出題内容が変わると混乱する。
その他はカンペや用語集サイトでググれば解けるような問題
数学の問題は中学でた人なら地頭良ければノー勉でも解けそう(ただ標準偏差などについて知っておく必要あり)
公式テキストに載っていない単語2割くらい・・・?合格できたかは5割ってとこです。
G検定対策 シラバスの用語ベースで問題つくろう#12【畳み込みニューラルネットワーク①】(ネオコグニトロン、LeNet)のコメント欄(https://youtu.be/0hz5t1aeECo)
このチャンネルには助けられました。ありがとうございました( *´艸`)
G検定 さっくり解説(真のG検定対策も)

G検定 さっくり対策(究極カンペの作り方)

G検定 出題傾向解説

G検定 法律問題対策(※動画作成環境のメモリ不足に伴い、前編後編に分離)


G検定 法律問題対策 前後編合体版

G検定 強化学習対策(概要編)

G検定対策 問題が無いなら作れば良いじゃないシリーズ



G検定 合否を分ける光と影(合格を勝ち取る人の傾向)

G検定超入門 とりあえず公式例題を解いてみるシリーズ



【見直し戦略が重要】G検定 試験画面について解説【試験前の最低限の前準備】

G検定対策 シラバスの用語ベースで問題つくろうシリーズ
シラバスの用語を元に過去問っぽい出題をする動画シリーズ。
ディープラーニングの社会実装に向けて
「AIと社会」(経営関連、法律関連、その他新技術関連)AI による経営課題の解決と利益の創出、法の遵守、ビッグデータ、IoT、 RPA、ブロックチェーン

「AIプロジェクトの進め方」(ビジネスとAI技術の板挟み関連)CRISP-DM、MLOps、DevOps、AIops、BPR、クラウド、Web API、データサイエンティスト、プライバシー・バイ・デザイン

「データの収集 前編」(法律問題、契約問題関連)オープンデータセット、個人情報保護法、不正競争防止法、著作権法、特許法、個別の契約、データの網羅性

「データの収集 後編」(契約問題関連)転移学習、サンプリング・バイアス、他企業や他業種との連携、産学連携、オープン・イノベーション、AI・データの利用に関する契約ガイドライン

「データの加工・分析・学習 前編」(匿名加工情報、カメラ画像利活用ガイドブック)アノテーション、匿名加工情報、カメラ画像利活用ガイドブック、ELSI、ライブラリ、Python

「データの加工・分析・学習 後編」(ツール、説明可能AI、ポリシー)Docker、Jupyter Notebook、説明可能AI(XAI)、フィルターバブル、FAT、PoC

「実装・運用・評価 前編」(法律問題、著作権法、不正競争防止法、個人情報保護法)著作物、データベースの著作物、営業秘密、限定利用データ、オープンデータに関する適用除外、秘密管理、個人情報

「実装・運用・評価 後編」(GDPR、攻撃、フェイク、バイアス)GDPR、十分性認定、敵対的な攻撃、ディープフェイク、フェイクニュース、アルゴリズムバイアス、ステークホルダーのニーズ

「クライシスマネジメント 前編」(炎上対策、軍事技術)コーポレートガバナンス、内部統制の更新、シリアスゲーム、炎上対策とダイバーシティ、AIと安全保障と軍事技術、実施状況の公開

「クライシスマネジメント 後編」(透明性レポート、Partnership on AI)透明性レポート、よりどころとする原則や指針、Partnership on AI、運用の改善やシステムの改修、次への開発と循環

数理・統計
「数理・統計」(統計検定3級程度の基礎的な知識)母集団、標本、平均、分散、標準偏差、帰無仮説

ディープラーニングの手法
「畳み込みニューラルネットワーク①」(ネオコグニトロン、LeNet)ネオコグニトロン、LeNet、サブサンプリング層、畳み込み、フィルタ

「畳み込みニューラルネットワーク②」(プーリング、Cutout、Random Erasing)最大値プーリング、平均値プーリング、グローバルアベレージプーリング、Cutout、Random Erasing

「畳み込みニューラルネットワーク③」(データ拡張、MobileNet、Neural Architecture Search)Mixup、CutMix、MobileNet、Depthwise Separable Convolution、NAS(Neural Architecture Search)

「畳み込みニューラルネットワーク④」(EfficientNet、NASNet、転移学習)EfficientNet、NASNet、MnasNet、転移学習、局所結合構造

「畳み込みニューラルネットワーク⑤」(ストライド、スキップ結合、パディング)ストライド、カーネル幅、プーリング、スキップ結合、各種データ拡張、パディング

「深層生成モデル」(GAN関連)ジェネレータ、ディスクリミネータ、DCGAN、Pix2Pix、CycleGAN

「画像認識分野①」(AlexNet、GoogLeNet、VGG)ILSVRC、AlexNet、Inceptionモジュール、GoogLeNet、VGG

「画像認識分野②」(ResNet、DenseNet、SENet)スキップ結合、ResNet、Wide ResNet、DenseNet、SENet

「画像認識分野③」(R-CNN、YOLO、SSD)R-CNN、FPN、YOLO、矩形領域、SSD

「画像認識分野④」(Faster R-CNN、各種セグメンテーション)Fast R-CNN、Faster R-CNN、セマンティックセグメンテーション、インスタンスセグメンテーション、パノプティックセグメンテーション

「画像認識分野⑤」(セグメンテーションの具体的なモデル)FCN (Fully Convolutional Netwok)、SegNet、U-Net、PSPNet、Dilation convolution

「画像認識分野⑥」(DeepLab、Open Pose、Mask R-CNN)Atrous Convolution、DeepLab、Open Pose、Parts Affinity Fields、Mask R-CNN

「音声処理と自然言語処理分野①」(LSTM、RNN Encoder-Decoder、BPTT)LSTM、CEC、GRU、双方向RNN、RNN Encoder-Decoder、BPTT

「音声処理と自然言語処理分野②」(Attention、PCM、FFT)Attention、AD変換、パルス符号変調、高速フーリエ変換、スペクトル包絡

「音声処理と自然言語処理分野③」(MFCC,フォルマント,音素)メル周波数ケプストラム係数、フォルマント、フォルマント周波数、音韻、音素

「音声処理と自然言語処理分野④」(隠れマルコフモデル、WaveNet、N-gram)音声認識エンジン、隠れマルコフモデル、WaveNet、メル尺度、N-gram

「音声処理と自然言語処理分野⑤」(BoW、TF-IDF、局所表現、分散表現)BoW(Bag-of-Words)、ワンホットベクトル、TF-IDF、単語埋め込み、局所表現、分散表現

「音声処理と自然言語処理分野⑥」(word2vec、fastText、ELMo)word2vec、スキップグラム、CBOW、fastText、ELMo

「音声処理と自然言語処理分野⑦」(Seq2Seq、Source-Target Attention、Encoder-Decoder Attention)言語モデル、CTC、Seq2Seq、Source-Target Attention、Encoder-Decoder Attention

「音声処理と自然言語処理分野⑧」(Self-Attention、位置エンコーディング、GPT-1,2,3)Self-Attention、位置エンコーディング、GPT、GPT-2、GPT-3

「音声処理と自然言語処理分野⑨」(BERT、GLUE、Vision Transformer、構文解析、形態要素解析)BERT、GLUE、Vision Transformer(ViT)、構文解析、形態素解析

【深層強化学習分野①】「DQN、デュエリングネットワーク、ノイジーネットワーク、Rainbow」DQN、ダブルDQN、デュエリングネットワーク、ノイジーネットワーク、Rainbow

「深層強化学習分野②」(モンテカルロ木探索、AlphaGo、AlphaGo Zero、Alpha Zero、マルチエージェント強化学習)

「深層強化学習分野③」(OpenAI Five、AlphaStar、状態表現学習、連続値制御、報酬成形)

「深層強化学習分野④」(オフライン強化学習、sim2real、ドメインランダマイゼーション、残差強化学習)

「モデルの解釈性、軽量化」(モデルの解釈、CAM、蒸留、モデル圧縮、量子化、プルーニング)

ディープラニングの概要
「ニューラルネットワークとディープラーニング」(単純/多層パーセプトロン、ディープラーニングとは、勾配消失問題、信用割当問題、誤差逆伝播法)

「ディープラーニングのアプローチ」(事前学習、積層オートエンコーダ、ファインチューニング、制限付きボルツマンマシン、深層信念ネットワーク)

「ディープラーニングを実現するには」(CPUとGPU、GPGPU、ディープラーニングのデータ量、TPU)

「活性化関数」(シグモイド関数、tanh関数、ReLU関数、ソフトマックス関数、Leaky ReLU関数)

「学習の最適化①」(学習率、誤差関数、交差エントロピー、イテレーション、エポック)

「学習の最適化②」(局所最適解、大域最適解、鞍点、プラトー、モーメンタム)

「学習の最適化③」(AdaGrad、AdaDelta、RMSprop、Adam、AdaBound、AMSBound)

「学習の最適化④」(ハイパーパラメータ、グリッドサーチ、ランダムサーチ、確率的勾配降下法、最急降下法)

「学習の最適化⑤」(バッチ学習、ミニバッチ学習、オンライン学習、データリーケージ)

「更なるテクニック①」(過学習、アンサンブル学習、ノーフリーランチの定理、二重降下現象、ドロップアウト)

「更なるテクニック②」(正規化、標準化、白色化、バッチ正規化、早期終了)

機械学習の具体的手法
「教師あり学習①」(分類問題、回帰問題、半教師あり学習、ラッソ回帰、リッジ回帰)

「教師あり学習②」(決定木、アンサンブル学習、ブートストラップサンプリング、バギング、勾配ブースティング)

「教師あり学習③」(マージン最大化、カーネル、カーネルトリック、活性化関数)

「教師あり学習④」(誤差逆伝播法、自己回帰モデル、ベクトル自己回帰モデル、隠れ層)

「教師あり学習⑤」(疑似相関、重回帰分析、AdaBoost、多クラス分類)

「教師なし学習①」(クラスタ分析、k-means法、ウォード法、デンドログラム)

「教師なし学習②」(レコメンデーション、協調フィルタリング、コンテンツベースフィルタリング、コールドスタート問題)

入門 数値解析シリーズ
【入門】行列の存在意義【数値解析】G検定、DS検定で行列嫌いの方々向け
ベクトル、行列、連立方程式、線形代数、数値解析、逆行列、掃き出し法

【入門】線形代数の基礎 前編【数値解析】G検定、DS検定で行列嫌いの方々向け
ベクトル、行列、線形代数、数値解析、内積、余弦定理、三角比の基本公式

【入門】線形代数の基礎 後編【数値解析】G検定、DS検定で行列嫌いの方々向け。ニューラルネットワーク、畳み込み、フーリエ変換も実は・・・。
ベクトル、行列、線形代数、数値解析、内積、連立方程式、ニューラルネットワーク、畳み込み、フーリエ変換、逆フーリエ変換

【入門】ベクトル行列演算(MATLAB,Python(NumPy))【数値解析】G検定、DS検定で行列嫌いの方々向け。ツールに任せれば一撃で解決!

2021年版、2024年版シラバスを比較してみた
単純比較はできなかったので、2021年版シラバスから見て。2024年版で増えた用語を抽出。
増えた用語について簡単に解説。

G検定 法律問題特化記事
受験者を魔境に引き込む法律問題の特化記事を作成。
個人情報保護法、著作権法、特許法、不正競争防止法についての概要とAIとの関連性について記載しているので参考にどうぞ。

G検定 強化学習特化記事
強化学習についての勉強方法を聞かれたんで、とりあえず記事にしてみた。

G検定超入門 とりあえず公式例題を解いてみる。
人工知能をめぐる動向 2問、人工知能分野の問題 2問の計4問

機械学習の具体的手法 4問、ディープラーニングの概要 3問の計7問

ディープラーニングの手法 5問、ディープラーニングの研究分野 2問の計7問

G検定の評判について
※ 読み飛ばし推奨!!
上司&同僚&部下からは特に不評なことは出てきてないが、SNS上では結構酷評されてる。
「G検定のGはゴキ〇リのGだ!!」
とか。
(気持ちは分からなくもない。一般的な試験だと問題集だけで対策としては十分なのだが、
G検定に関してはその経験が結構邪魔をする・・・。)
ゴキ〇リを舐めていけない。
擬人化すると結構かわいいのだ。

身構えるゴキ〇リ

空飛ぶゴキ〇リ
ちゃんとデザイン案もある。(すごい。)
※画像は以下のサイトより拝借致しました。

世の中のG検定の位置づけ
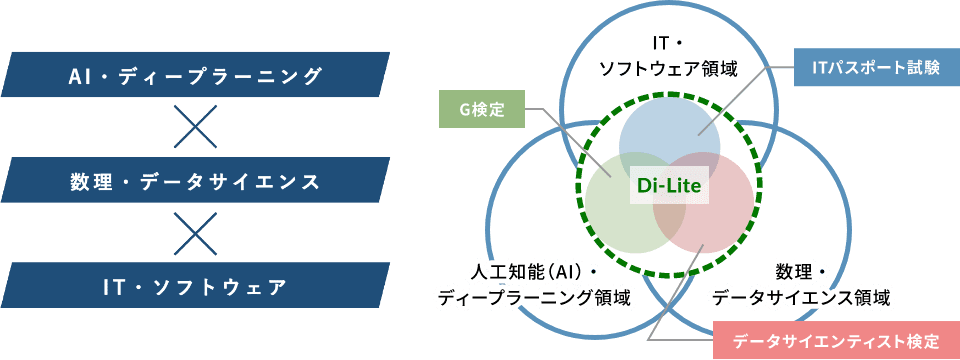
経済産業省がオブザーバーとなっている、デジタル人材育成を目的としたデジタルリテラシー協議会というものがある。
そこでデジタルリテラシーDi-Lite(ディーライト)について語られている。

詳細説明は割愛するが、AI、データサイエンス、ITの3つの分野を横断するような人材が求められているということになる。
G検定はこの中でAI・ディープラーニングの領域のリテラシーを保有していることを証明する検定という位置づけになっている。
G検定の難易度について
まずは難易度としてはそれほど難しいものではない。
後の方にも書いてるが、合格率は60%かそれより上なので、まじめに且つ適切に対策していれば問題無いレベルと言える。
ただ、受験者の獲得点数の分布を散らしたいという出題者側の意向がありそうで、問題自体は難しかったり、単語を暗記してる程度では解けないような複合的な出題の仕方になっているので、対策の仕方が単純暗記では乗り越えられないと思った方が良い。
問題の傾向、予想合格ラインも本記事に記載しているので、そこからG検定の難易度を読み取っていただければと思う。
情報量としてはかなりあるので、お手隙に少しずつでも読んでいただければ。
オープンバッジの付与
2021年10月25日以降よりG検定合格者に対してオープンバッジが付与されることとなった。
これは過去の合格者に対しても適用されており、私に対しても付与された。
株式会社LecoSのオープンバッジウォレットサービスにて監視されている物らしい。
まぁこれがあるからといって現状では特に優遇されるものはないと思うが、こういうものが存在して、それを付与してもらったというのは中々趣がある。
今後の検定、資格関連は同様にオープンバッジとして付与されるようになるのかもしれない。
一応、オープンバッジの説明↓
オープンバッジ(Open Badges)は、技術標準規格にそって発行されるデジタル証明/認証。資格情報をSNSなどで共有、オープンバッジの内容証明を行うことが可能。もともとはMozillaがマッカーサー財団からの資金提供を受けて開発した規格。オープンバッジ標準では、成果に関する情報をアーカイブして画像ファイル(png、svg)にメタ情報を埋め込むこと。また、バッジ検証のためのインフラを確立する方法について説明している。この標準は2017年1月1日をもって正式にIMS Global Learning Consortiumに移行した。
Wikipediaより(https://ja.wikipedia.org/wiki/%E3%82%AA%E3%83%BC%E3%83%97%E3%83%B3%E3%83%90%E3%83%83%E3%82%B8)
過去問っぽい問題集(ひたすら過去問ふぅ問題で鍛錬する所 一問一答 仮)
勝手に過去問っぽい問題集作成中。実際の問題よりかは難易度低め。
※ 問題の種類は法規/近年の動向にかなり寄せてる。普通の問題を解きたい方は既存お問題集や模試サイトをやった方が良い。実際のG検定を受けた際に時事問題、法規問題に直面した際にショックを受ける方が多いようなので、そのショックをいくらか軽減する目的で設置。
公式テキストや問題集に載ってないような文言が出てくるが、AI白書やarXiv等の文献で出てくるような言い回しを採用しているため。
G検定で求めれるジェネラリストとしては、割と必要と判断しても良い表現だと思う。
(G検定問題文も全てではないが、4割くらいはそんな感じ)
尚、初見では誤答する方が普通。
パッと見わからないのであれば、Google検索してみるのもアリ。
重要なのは、「問題文と答えの関係性だけを暗記する」のだけは避けるべき。
言い回しの違いで知ってるはずなのに解けない現象が発生する。
あと、問題文より選択肢側に罠が仕掛けられていることもしばしば。
選択肢としては消去法で2つまでは容易に絞れて、その後に特定の論点をもって優劣を決定させるパターンを出題者は好む傾向がある。
出題者側からするとこのパターンの出題ができるとうまくハマった感が出るため。
この出題者の趣味趣向を逆手にとって解くというのも一手だろう。
※これは、他の問題集を解くときも一緒。
一応無料です。私が趣味の範疇で書き起こしているだけなので。
法律関連の過去問っぽい問題も入れ始めた。
※ 現在690問程放り込んでる。(新しいネタが見つかり次第随時追加中)

本問題集とYoutube動画を連携させた利用方法の解説動画


AI白書。(用語検索を考えるとkindle版の方が良いかも)

arXivに上がっているような論文を読む際は、
- Introduction(導入文)
- Related Work(関連研究)
のような章がある。
特にRelated Work(関連研究)は過去の経緯などが記載されており、そのくだりがG検定等の問題の表現に近いことがある。
私の所感だが、どうもG検定で求めているスキルのラインはarXivの論文がそこそこ読めるあたりに引いているように感じる。
他ブログやTwitter上でG検定に対して否定的な意見もそこそこあるが、それはそれでその方々の主観/意見であるので否定する気は無い。
しかし、それに引きずられて他人の意見を鵜呑みにして、自身の意見としてしまう前に、今の世の中を見て、何を求めれているのか、どうあれば胸を張ってジェネラリストと言えるのか、という点を一考した方が良いだろう。
arXivを利用した情報収集方法例
「Occlusion Handling in Generic Object Detection: A Review」
を例に挙げる。

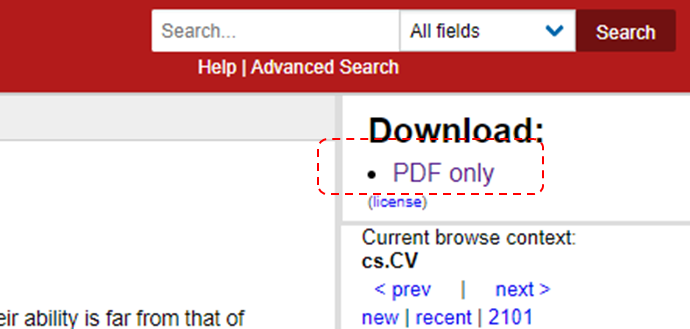
左上からPDFの論文がDownloadできる。
この論文のIntroductionの一部を抜粋。
Object detectors are categorized into two types: one-stage detectors, and two-stage detectors. The latter uses region proposal network to produce regions of interest (ROI) and apply a deep neural network to classify each proposal into class categories. The first type, however, considers the object detection as a regression problem, hence it uses a unified framework to learn the class probabilities and coordinates of bounding boxes. This makes one-stage detectors faster compared to its counterpart. The most effective state-of-art detectors are Faster RCNN, SSD and YOLO.
Occlusion Handling in Generic Object Detection: A Review https://arxiv.org/abs/2101.08845
↓日本語訳
物体検出器は、1段階検出器と2段階検出器の2種類に分類される。
後者は、領域提案ネットワークを用いて関心領域(ROI)を生成し、ディープニューラルネットワークを用いて各提案をクラスカテゴリに分類する。
一方、1段階検出器は、物体検出を回帰問題として捉え、クラス確率とバウンディングボックスの座標を統一的なフレームワークで学習する。
これにより、1段階検出器は、他のタイプの検出器よりも高速になる。
最先端の検出器としては,Faster RCNN、SSD、YOLOなどが挙げられる。
これだけで、物体検出器のおおよその分類/性格/関係性が見て取れる。
何となく単語だけで覚えるよりも、はるかに効率的に学習が進むと思われる。
(※G検定対策に特化した場合は、当然非効率にはなるが・・・)
その他のAI関連記事
LSTMを使用した日経平均株価の予測の記事もかいてるので、興味ある方はこちらからどうぞ。

G検定を受ける前準備について
以下の記事で、G検定受験に必要なブラウザ、画面解像度、回線速度について記載。
あと、要らぬリスクを追わないようにするための対策例。
そして、試験画面についてや、試験時の見直し戦略について記載している。
受験予定の人は斜め読みで良いので読んでおいた方が良いでしょう。

次のページへ
次のページから各年の傾向、感想、テキスト、問題集等


コメント
It’s hard to find educated people about this subject, however, you seem like you know what you’re talking about!
Thanks