
G検定対策のまとめ記事はこちら。
https://www.simulationroom999.com/blog/jdla-deep-learning-for-general-2020-1/

はじめに
G検定超入門 とりあえず公式例題を解いてみる#1
の続き。
本記事では全18問中の
機械学習の具体的手法 4問
ディープラーニングの概要 3問
の合計7問まで。
G検定 公式例題

その他の例題
人工知能をめぐる動向 2問、人工知能分野の問題 2問の計4問

ディープラーニングの手法 5問、ディープラーニングの研究分野 2問の計7問

機械学習の具体的手法(1問目)
問題
Q. 以下の文章は、さまざまな機械学習の手法について述べたものである。空欄に最もよく当てはまる選択肢を、語群の中から1つずつ選べ。
G検定の例題(https://www.jdla.org/certificate/general/issues/)
機械学習にはいくつかの手法があり、用語の意味を正しく理解する必要がある。学習データに教師データと呼ばれる正解ラベルつきのデータを用いる手法は(ア)と呼ばれ、対照的に正解ラベルがないデータを利用する手法は(イ)と呼ばれる。また、正解ラベルが一部のサンプルにのみ与えられている(ウ)という手法も存在する。
1. 教師なし学習
2. 教師あり学習
3. 強化学習
4. 表現学習
5. マルチタスク学習
6. 半教師あり学習
7. 多様体学習
解答
(ア)2
(イ)1
(ウ)6
解説
(ア)(イ)は問題文に書いてある通りで、
教師あり学習は、正解ラベル付きデータを使用し、教師なし学習は正解ラベルがないデータを使用して学習する。
半教師あり学習は、トレーニング中に少量のラベル付きデータと大量のラベルなしデータを組み合わせる機械学習へのアプローチ。
大きく2パターンに分かれ、以下が存在する。
パターン1
- 教師なし学習で特徴表現を獲得
- その後、教師ありでそのモデルを再学習する方法
パターン2
- 教師ありデータを使ってモデルを作る。
- そのモデルで教師なしデータの推論を得る。
- その推論の中で精度の高いデータを正解ラベルとする。
- これを教師ありデータとしてモデルを再学習する。
機械学習の具体的手法(2問目)
問題
Q. 以下の空欄に最もよく当てはまる選択肢を、語群の中から1つずつ選べ。
G検定の例題(https://www.jdla.org/certificate/general/issues/)
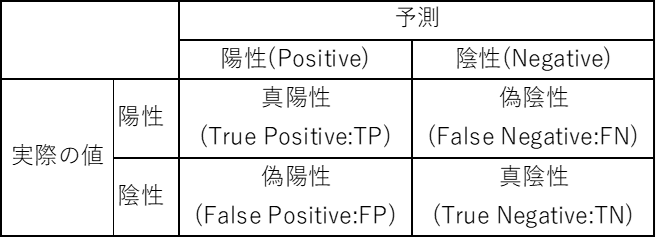
分類問題にはさまざまな性能指標がある。ここでは、サンプルを陽性(Positive)と陰性(Negative)の2クラスに分ける2値分類を考える。(ア)は単純にサンプル全体のうち、予測が正解したサンプル数の比を取ったものである。また、偽陽性(False Positive, FP)を減らすことに特に注力したい場合には(イ)を、逆に偽陰性(False Negative, FN)を減らすことに特に注力する場合には(ウ)を採用することが望ましい。しかし、この両者はトレードオフの関係にあることから、それらの調和平均を取った(エ)が利用されることも多い。
1. 正答率
2. 実現率
3. 協調率
4. 調和率
5. 適合率
6. 再現率
7. f値
8. p値
9. t値
10. z値
解答
(ア)1
(イ)5
(ウ)6
(エ)7
解説
ここの問題は呼び名の話なので、覚えるしかない。
しかも別の言い方や英語表現もあったりで、
地味に間違いを誘う問題になりやすい・・・。
以下も合わせて覚えないと結構きつい。
真陽性:予測値がPositive、実際の値がPositive。True Positive(TP)
偽陰性:予測値がNagative、実際の値がPositive。False Nagative(FN)
偽陽性:予測値がPositive、実際の値がNagative。False Positive(FP)
真陰性:予測値がNagative、実際の値がNagative。True Nagative(TN)
(ア)について
これは「正答率」になる。「正解率」という場合もあるし、「accuracy」という場合もある。
\(
accuracy=\displaystyle\frac{TP+TN}{TP+TN+FP+FN}
\)
\(TP+TN+FP+FN\)がサンプル全数で、\(TP+TN\)が正解数
(イ)について
「適合率」は「precision」とも言う。
\(
precision=\displaystyle\frac{TP}{TP+FP}
\)
\(TP+FP\)のPositiveと予測したもののうちで\(TP\)の実際にPositiveだったもの割合となる。
(ウ)について
「再現率」は「recall」とも言う。
\(
recall=\displaystyle\frac{TP}{TP+FN}
\)
\(TP+FN\)の実際にPositiveだったもの全てのうち、予測がPositive且つ実際の値もPositiveだったものの割合。
適合率と再現率はトレードオフの関係になる。
(エ)について
「f値」、または「Fmeasure」とも言う。
\(
Fmeasure=\displaystyle\frac{2 \times precision \times recall}{precision+recall}
\)
これは適合率と再現率の調和平均。
機械学習の具体的手法(3問目)
問題
Q. 機械学習では、教師データをいくつかに分割して、そのうち一部だけを学習に利用するのが原則である。逆に言えば、その他の教師データはあえてモデルの学習に利用せずに、残しておく。そのような手法を採用する目的として、最も適切なものを1つ選べ。
G検定の例題(https://www.jdla.org/certificate/general/issues/)
1. いったん少ないデータ量で学習させ、初期段階の計算資源を節約するため。
2. データの中に含まれる異常値を持つサンプルを取り除くため。
3. 半教師あり学習はデータの一部がラベル付けされていなくても行えるため。
4. モデルが運用される際に示す性能を正しく見積もるため。
解答
4
解説
機械学習全般での重要ステップとして、学習済みモデルが未知のデータに対して予測できるか評価するものがある。
この未知のデータに対する予測精度を汎化性能と呼ぶ。
この汎化性能を評価するためには学習に使用していないテストデータが必要となる。
このことを本問題では問うている。
手法としては、
単純に訓練データとテストデータを8:2または9:1に分ける、ホールドアウト検証や
複数回の学習で訓練データとテストデータの分け方を変える、k-分割交差検証などが代表的。

機械学習の具体的手法(4問目)
問題
Q. 空欄に当てはまる語句の組み合わせとして最も適しているものを1つ選べ。
G検定の例題(https://www.jdla.org/certificate/general/issues/)
教師あり学習の問題は出力値の種類によって、大きく2種類に分けられる。(A) 問題は出力が離散値であり、カテゴリーを予測したいときに利用される。一方、(B) 問題は出力が連続値であり、その連続値そのものを予測したいときに利用される。
1. (A) 限定 (B) 一般
2. (A) 部分 (B) 完全
3. (A) 分類 (B) 回帰
4. (A) 線形 (B) 非線形
解答
3
解説
教師あり学習は、分類と回帰に分けることができる。
分類は、入力データを元に特定のラベルに振り分けるものを指す。
例えば、画像を入力として犬、猫に分けるなど。
回帰は、入力データを元に気温や株価などの連続的なデータを補完、予測するもの。
回帰が、必ず連続値かと問われると例外もありそうだが、
入力データを元に特定の近似線や関数に同定することを指すので、分類と比べれば連続性はあると言える。
ディープラーニングの概要(1問目)
問題
Q. 近年急速にディープラーニングが高い成果を上げるようになった理由として当てはまるものを全て選べ。
G検定の例題(https://www.jdla.org/certificate/general/issues/)
1. 半導体技術の進歩による計算機の性能向上やGPUによる高速な並列演算により、現実的な時間で学習を行うことができるようになったため。
2. 神経科学の発展により、画像認識や自然言語処理に対する視覚野や言語野など、タスクに対応した人間の脳の構造を実物通りに再現できるようになったため。
3. インターネットの普及により、表現力の高いモデルが過学習を起こさずにすむ大量のデータを得ることができるようになったため。
4. 誤差逆伝播法の発明によってそれまで困難だった多層ニューラルネットワークの訓練が可能になったため。
5. ディープラーニング向けのフレームワークが多数開発され、実装が容易になったため。
解答
1,3,5
解説
1について
半導体技術の進歩の影響はかなり大きい。
CPU自体の高性能化に加え、GPU、TPUによる並列演算で学習時間が大幅に削減される。
Google Colaboratory上でCPU onlyとGPU or TPU併用した場合、体感ではあるが、10倍以上の差が出る。
2について
ニューラルネットワークは脳のニューロンを元にしたモデルと言われており、無関係というわけではない。
しかし、「神経科学の発展により」というのは違うし、「人間の脳の構造を実物通りに再現」したものでもない。
3について
インターネット普及に伴うビッグデータの貢献を指したもの。
少量データでは汎化性能が得られず過学習になりやすい。
4について
書いている内容としては正しいが、
「近年」と「ディープラーニング」を加味すると間違っていることになる。
誤差逆伝播法(バックプロパゲーション)自体は1986年からあるもので、
ディープラーニングは2006年に登場したもの。
時間軸があっていないというのが理由となる。
CPUの処理性能の都合で発明当初は実用的でなかったところに、
半導体技術の進歩によって近年に脚光を浴びたという経緯はある。
バックプロパゲーション

5について
記載通り。
Caffe,Tensorflow,Chainer,Pytorchなどのフレームワークにより実装が楽になっている
NVIDIAのCUDAライブラリによるGPU制御もこれを後押ししており、
各フレームワークは利用者にCUDAの存在を見せずに、結果としてGPUを意識せず利用することが可能になっている。
ディープラーニングの概要(2問目)
問題
Q. 以下の文章を読み、空欄に最もよく当てはまる選択肢を1つずつ選びなさい。
G検定の例題(https://www.jdla.org/certificate/general/issues/)
従来の機械学習で利用されていた最適化手法である最急降下法は、一度の学習にすべてのデータを利用することから(ア)と呼ばれている。しかし、ディープラーニングの場合データが大規模であることからそれが難しい。よって、確率的勾配降下法という手法が用いられることも多い。ひとつのサンプルだけを利用する手法は(イ)と呼ばれる。(ア)と(イ)は、どちらにも長所と短所があり、一定数のサンプル群を利用する(ウ)が採用されることが推奨される。
1. セット学習
2. バッチ学習
3. オンライン学習
4. ポイント学習
5. サンプリング学習
6. ミニバッチ学習
解答
(ア)2
(イ)3
(ウ)6
解説
(ア)について
バッチ学習は、全てのデータを一括投入してモデルを学習する手法。
かなり安定した学習が可能だが、
学習に費やす計算時間は非常に長くなるのとメモリ使用量が多くなるため、モデルの学習と予測を分けて行うのが特徴的。
(イ)
オンライン学習はデータをランダムに1個ずつ投入してモデルを学習する手法。
オンラインと名がついている通り、リアルタイムでモデル更新を頻繁に行うケースにも適用しやすい特徴がある。
反面、1データ単位の計算速度はバッチ学習に劣るのと、リアルタイムにデータを入力する際に異常値が混入するリスクがある。
(ウ)
ミニバッチ学習は、データを小さなグループに分割投入してモデルを学習する手法。
特徴はバッチ学習とオンライン学習のちょうど中間。
ディープラーニングの概要(3問目)
問題
Q. あるニューラルネットワークのモデルを学習させた際、テストデータに対する誤差を観測していた。そのとき、学習回数が100を超えるまでは誤差が順調に下がり続けていたが、それ以降は誤差が徐々に増えるようになってしまった。その理由として最も適切なものを1つ選べ。
G検定の例題(https://www.jdla.org/certificate/general/issues/)
1. 学習回数が増えるほど、誤差関数の値が更新されにくくなるため。
2. 学習回数が増えるほど、学習データにのみ最適化されるようになってしまうため。
3. 学習回数が増えるほど、一度に更新しなければならないパラメータの数が増えていくため。
4. 学習回数が増えるほど、計算処理にかかる時間が増えてしまうため。
解答
2
解説
1について
その通りではあるのだけども、だからと言って誤差が増える状況を生むわけではないので違う。
2について
いわゆる過学習で、これが答えと考えるのが妥当。
学習データに特化した結果としてテストデータに対しての誤差が大きくなった状態。
3について
ニューラルネットワークに於いて、更新するパラメータが変化することはない。
更新するパラメータ数はユニット数、レイヤー数で決定される。
4について
学習回数が増えても計算処理にかかる時間が増えることはない。
確かに微妙に変化することはあるが、
これが誤差が増える原因にはならない。
まとめ
- 教師あり学習の分類と回帰、教師なし学習のクラスタリングのカテゴリ分けとおれぞれの性質は把握しておいた方が良い。
- ディープラーニングの発展の歴史に半導体技術発展、フレームワークの存在がある。
- 機械学習の学習時の手順や課題を把握する必要がある。
G検定対策のまとめ記事はこちら。


コメント