
https://www.simulationroom999.com/blog/jdla-deep-learning-for-general-2020-1/

はじめに
ディープラーニングの研究分野の一つである、自然言語処理分野について記載する。
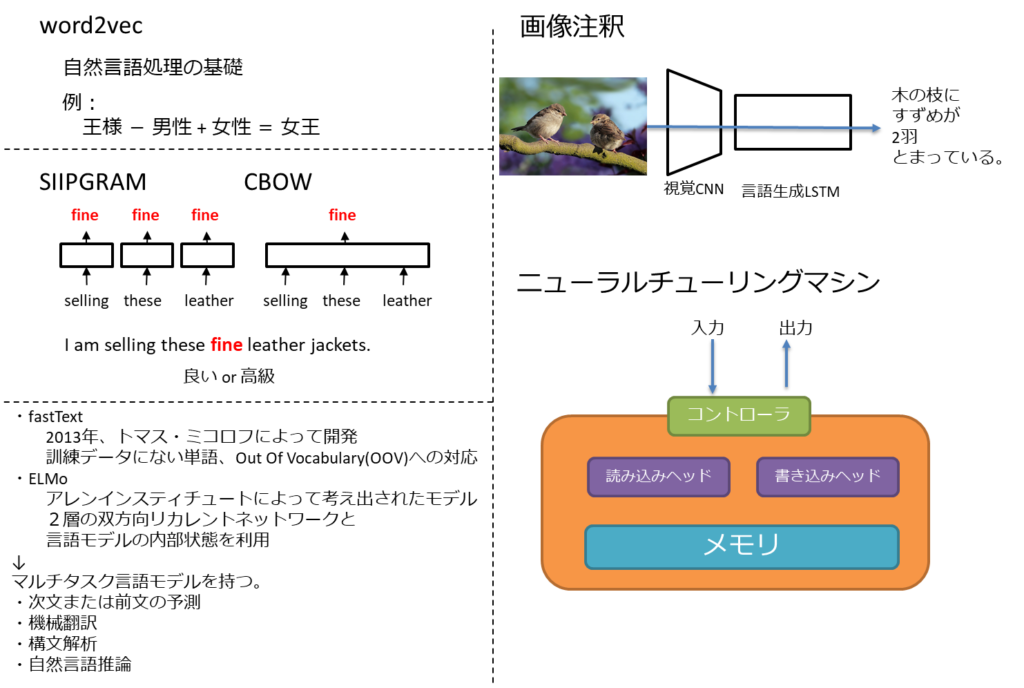
ベクトル空間モデル
word2vecは、「単語→ベクトル」の意で、ベクトル空間モデルや単語埋め込みモデルとも言われている。
単語の意味は、その周辺の単語によって決まる
という言語学の主張をニューラルネットワークで実現したもの。
有名な例は以下
王様 - 男性 + 女性 = 女王
word2vecには2種類の手法がある。
- スキップグラム(Skip-gram)
- 単語から周辺の単語を予測する
- CBOW
- 周辺の単語から単語を予測する。
文書の意味表現
word2vecにより、単語埋め込みモデルは爆発的に発展した。
よって、word2vecは自然言語処理(natural language processing:NLP)の基礎と考えることができる。
word2vecには2つの後継モデルが存在。
- fastText
- 2013年、トマス・ミコロフによって開発
- 訓練データにない単語、Out Of Vocabulary(OOV)への対応
- ELMo
- アレンインスティチュートによって考え出されたモデル
- 2層の双方向リカレントネットワークと言語モデルの内部状態を利用
共通の性質としてマルチタスク言語モデルを持つ。
- 次文または前文の予測
- 機械翻訳
- 構文解析
- 自然言語推論
画像の注釈付け
ニュートラル画像脚注付け(Neural Image Captioning:NIC)
CNNとRNNの言語モデルを組み合わせたもの
シーケンス2シーケンス(Seq2Seq)
自動翻訳技術として良く用いられる
ニューラルチューリングマシン(Neural Turing Machines:NTM)
LSTMを利用したコントローラを配置して、系列制御、時系列処理などの複雑な内容を解くことができる。
まとめ
- 自然言語処理の基礎はword2vecことベクトル空間モデル、単語埋め込みモデル
- 発展形のfastText、ELMoはマルチタスク学習が可能
- 画像注釈はCNNとRNNの連携で実現


コメント