
バックナンバーはこちら。
https://www.simulationroom999.com/blog/compare-matlabpythonscilabjulia4-backnumber/

はじめに
形式ニューロン且つ総当たり法によるパラメータ特定のプログラム化
今回はPython(NumPy)で実現。
登場人物
博識フクロウのフクさん

イラストACにて公開の「kino_k」さんのイラストを使用しています。
https://www.ac-illust.com/main/profile.php?id=iKciwKA9&area=1
エンジニア歴8年の太郎くん

イラストACにて公開の「しのみ」さんのイラストを使用しています。
https://www.ac-illust.com/main/profile.php?id=uCKphAW2&area=1
【再掲】処理フロー
太郎くん
まずは処理フローを再掲。
- 入力データセットの定義
- 出力データセットの定義
- パラメータ変数の定義(重み、バイアス)
- 学習率定義
- 重みとバイアスの総当たり計算(ループ)
- 重みとバイアスを使用して予測値を算出
- 損失の計算
- 損失の更新
- 最も損失が小さいパラメータの記憶
- 学習結果の表示
- 出力結果の確認
フクさん
これをPython(NumPy)で実現する。
Pythonコード
フクさん
Pythonコードは以下。
import numpy as np
import matplotlib.pyplot as plt
# データセットの入力
X = np.array([[0, 0], [0, 1.0], [1.0, 0], [1.0, 1.0]])
# データセットの出力
Y = np.array([0, 0, 0, 1])
# パラメータの初期値
W = np.zeros((2, 1)) # 重み
b = 0 # バイアス
num_epochs = 10000 # 学習のエポック数
learning_rate = 0.1 # 学習率
min_loss = float('inf')
learning_range = 4
n = len(Y)
# 重みの総当たり計算
for w1 in np.arange(-learning_range, learning_range + learning_rate, learning_rate):
for w2 in np.arange(-learning_range, learning_range + learning_rate, learning_rate):
for b in np.arange(-learning_range, learning_range + learning_rate, learning_rate):
# フォワードプロパゲーション
Z = np.dot(X, np.array([[w1], [w2]])) + b # 重みとバイアスを使用して予測値を計算
A = np.heaviside(Z, 0) # ヘヴィサイド活性化関数を適用
# 損失の計算
loss = (1/n) * np.sum((A - Y.reshape(-1,1))**2) # 平均二乗誤差
# 最小損失の更新
if loss < min_loss:
min_loss = loss
best_w1 = w1
best_w2 = w2
best_b = b
# ログの表示
print(f'loss: {min_loss}')
print(f'weight: w1 = {best_w1}, w2 = {best_w2}')
print(f'bias: b = {best_b}')
# 最小コストの重みを更新
W = np.array([[best_w1], [best_w2]])
b = best_b
# 学習結果の表示
print('learning completed')
print(f'weight: w1 = {W[0]}, w2 = {W[1]}')
print(f'bias: b = {b}')
# 出力結果確認
print(f'X={X}')
result = np.heaviside(np.dot(X, W) + b, 0)
print(f'hatY={result}')
# 分類境界線のプロット
x1 = np.linspace(-0.5, 1.5, 100) # x1の値の範囲
x2 = -(W[0] * x1 + b) / W[1] # x2の計算
plt.figure()
plt.scatter(X[Y == 0, 0], X[Y == 0, 1], c='r', label='Class 0', marker='o')
plt.scatter(X[Y == 1, 0], X[Y == 1, 1], c='b', label='Class 1', marker='o')
plt.plot(x1, x2, 'k', linewidth=2)
plt.xlim([-0.5, 1.5])
plt.ylim([-0.5, 1.5])
plt.title('Decision Boundary')
plt.legend()
plt.grid()
plt.show()
処理結果
フクさん
処理結果は以下。
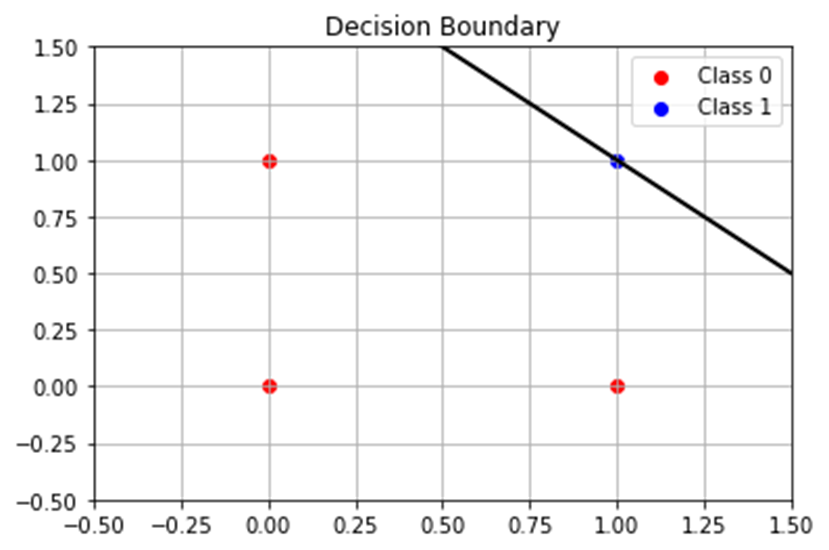
weight: w1 = [0.1], w2 = [0.1]
bias: b = -0.19999999999999662
X=[[0. 0.]
[0. 1.]
[1. 0.]
[1. 1.]]
hatY=[[0.]
[0.]
[0.]
[1.]]考察
太郎くん
結果はMATLABと一緒だね。
太郎くん
ただ、バイアスがちょっと違うのかな?
フクさん
これは表示桁数の違いによって、演算誤差の見え方が異なっているように見えているだけだな。
太郎くん
つまり、MATLABと同じ結果は得られていると見てOKってことか。
フクさん
そうそう。
そして、決定境界直線の位置がギリギリと言う問題も一緒だな。
まとめ
フクさん
まとめだよ。
- 形式ニューロンをPython(NumPy)で実現。
- ANDの真理値表と同じ結果が得らえれた。
- そして、決定境界線はギリギリな感じはMATLABのときと一緒。
バックナンバーはこちら。


コメント