
バックナンバーはこちら。
https://www.simulationroom999.com/blog/compare-matlabpythonscilabjulia4-backnumber/

はじめに
ニューラルネットワークの最適化アルゴリズムについて。
実際にプログラムでモーメンタムを動作させたので、
通常の勾配降下法とモーメンタムの差分を確認しておく。
登場人物
博識フクロウのフクさん

イラストACにて公開の「kino_k」さんのイラストを使用しています。
https://www.ac-illust.com/main/profile.php?id=iKciwKA9&area=1
エンジニア歴8年の太郎くん

イラストACにて公開の「しのみ」さんのイラストを使用しています。
https://www.ac-illust.com/main/profile.php?id=uCKphAW2&area=1
モーメンタムのプログラムを実行してみた感じ
最適化アルゴリズムを通常の勾配降下法からモーメンタムにしても
ちゃんと分類はできたね。
でも、そうなると何が差分かというのも良くわからんな・・・。
差分はある。
モーメンタムにしたことによる差分
どんな差分があったっけ?
学習の収束速度が大幅に上がってるな。
そういえば、誤差関数の値もグラフにしてたね。
このグラフの動き方が違ってたってこと?
そうそう。
勾配降下法でやった場合と、
モーメンタムでやった場合のグラフを比較してみよう。
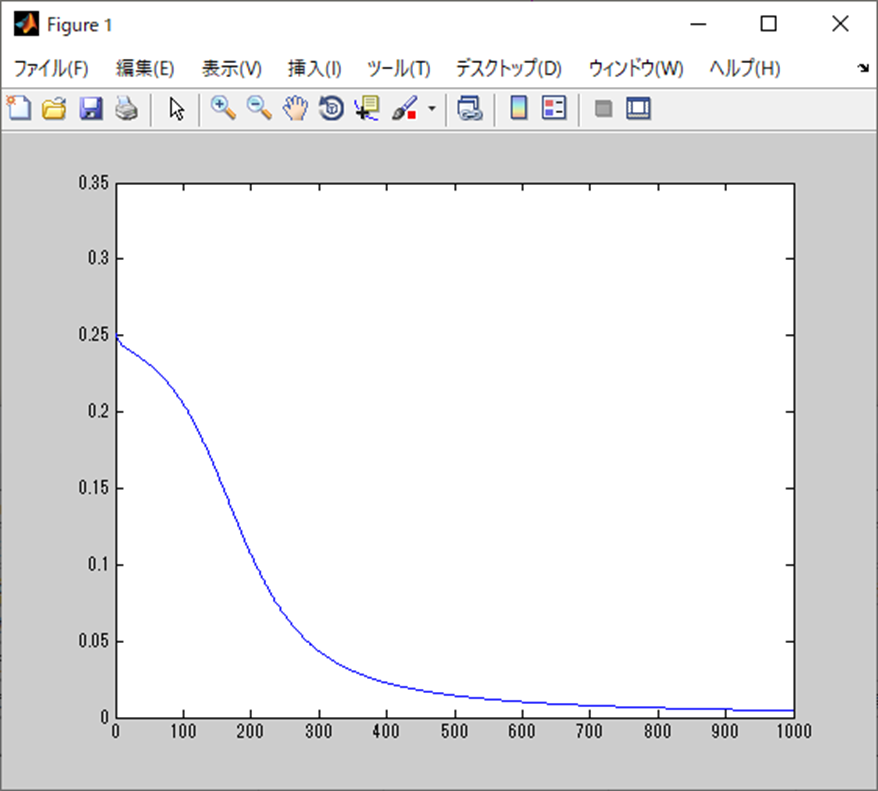
勾配降下法の場合
モーメンタムの場合
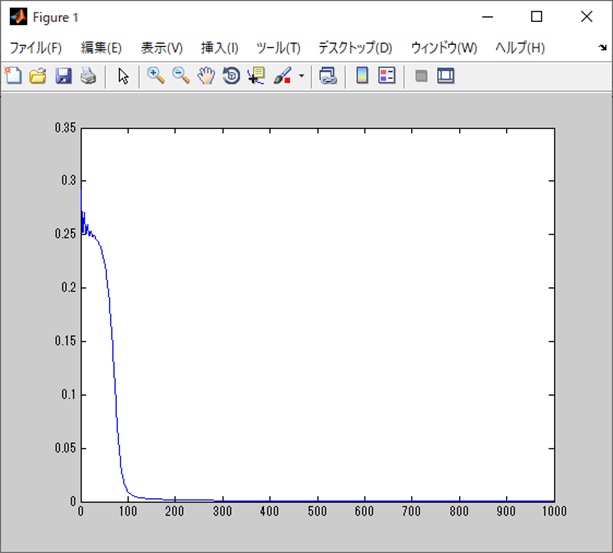
なんか全然違う!
勾配降下法はおおよそ500エポックあたりで収束だが、
モーメンタムは100エポックあたりで収束だな。
収束の仕方も一気に進んでいる。
これがモーメンタムの勢いをのせた結果だろう。
あとは、モーメンタムの方は初期段階では割と誤差関数の結果が暴れてる気がするね。
初期段階だと誤差関数の移動範囲が大き目に出るからね。
その分大域最適解を探せる可能性があるとも言えるんだろうね。
まぁ、今回の構造だと、これの効能は目立って出ることはないだろうけど。
ネットワークが複雑になると効果ありそうってことか。
あとは学習データが大量にあって、
その都合でミニバッチ学習、オンライン学習を採用する際も効果があるのだろう。
今回は学習データを一括で扱うバッチ学習って方式だったね。
学習方式によってもそこらへんは変わるのか。
というわけで、モーメンタムのは話はここで終了。
まとめ
まとめだよ。
- 最適化アルゴリズムを通常の勾配降下法からモーメンタムに変えた際の差分を確認。
- モーメンタムの方が学習の収束が早い。
- 勾配降下法で500エポックのところ100エポック。
- モーメンタムの場合、初期のパラメータ移動が大き目。
- これにより、大域最適化を見つける可能性が高くなる。
- モーメンタムの方が学習の収束が早い。
バックナンバーはこちら。
Pythonで動かして学ぶ!あたらしい線形代数の教科書

ゼロから作るDeep Learning ―Pythonで学ぶディープラーニングの理論と実装

ゼロからはじめるPID制御

OpenCVによる画像処理入門

恋する統計学[回帰分析入門(多変量解析1)] 恋する統計学[記述統計入門]

Pythonによる制御工学入門

理工系のための数学入門 ―微分方程式・ラプラス変換・フーリエ解析



コメント