
※ G検定についてのまとめ記事はこちら
https://www.simulationroom999.com/blog/jdla-deep-learning-for-general-2020-1/

はじめに
前回の続き。
ただし、今回の問題点はディープラーニングにより解決されているものも含まれる。
- 知識獲得のボトルネック
- 特徴量設計の問題
- シンギュラリティ(技術的特異点)
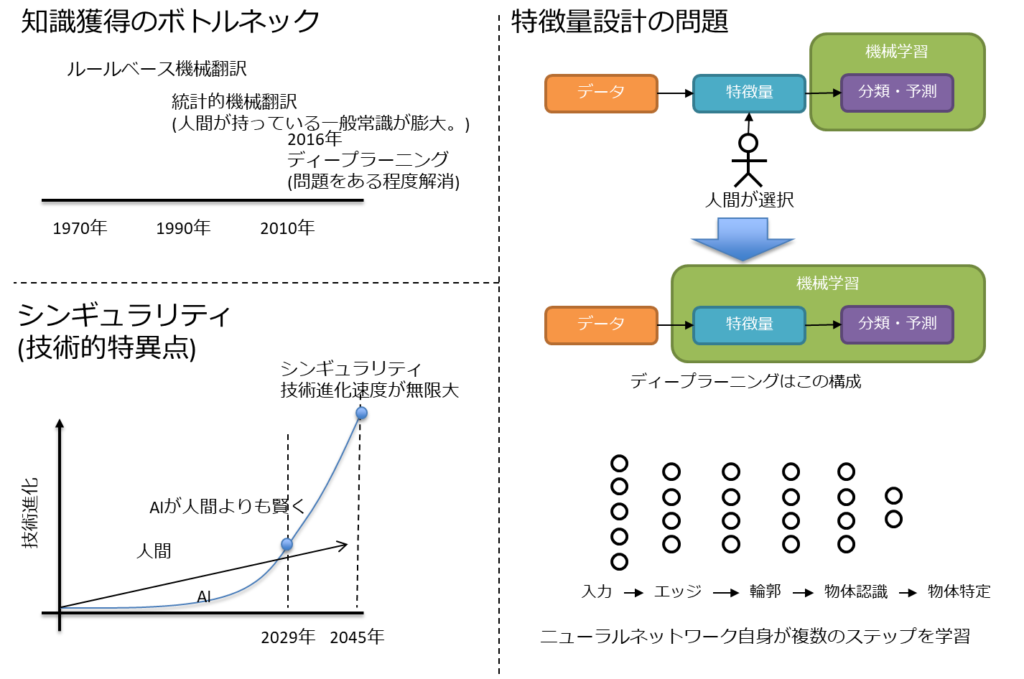
知識獲得のボトルネック
機械翻訳の歴史は以下となる。
- 1970年代後半:ルールベース機械翻訳
- 1990年代以降:統計的機械翻訳
- コンピュータが「意味」を理解しているため、この段階ではまだ実用レベルではない。
- 人間が持っている一般常識が膨大。
- これを知識獲得のボトルネックと呼ぶ
- 2016年:ディープラーニングのニューラル機械翻訳はこの問題を乗り越えた
- TOEIC900点以上相当。
特徴量設計の問題
特徴量とは、注目すべきデータの特徴を量的に表したものであり、これの選び方が性能に大きく影響する。
正しい特徴量を見つけ出すのは非常に困難であったが、機械学習自身に特徴量を発見させるアプローチとして、特徴表現学習でうまく対策している。
ディープラーニングはそれの一つになる。
また、ニューラルネットワーク自身が複数のステップを学習するため、その一部に特徴表現学習を組み込むのは比較的容易と言える。
シンギュラリティ(技術的特異点)
シンギュラリティ(技術的特異点)とは、以下を指し示す。
人工知能が十分に賢くなり、自分自身よりもエライ人工知能を作るようになった瞬間、無限に知能の高い存在を作る。
未来学者レイ・カーツワイルは以下を主張している。
- 2045年にシンギュラリティと主張
- 人工知能が人間よりも賢くなる年は2029年と主張
※ 特異点=ある基準が適用できなくなる点
まとめ
- 解決していない問題はあるが、ディープラーニングにより解決した問題も多い
- シンギュラリティ(技術的特異点)はもうすぐ。


コメント