
https://www.simulationroom999.com/blog/jdla-deep-learning-for-general-2020-1/

G検定対策はこちら
はじめに
AIプロダクト開発の工程を通じて関連する法律、倫理、現行の議論について記載する。
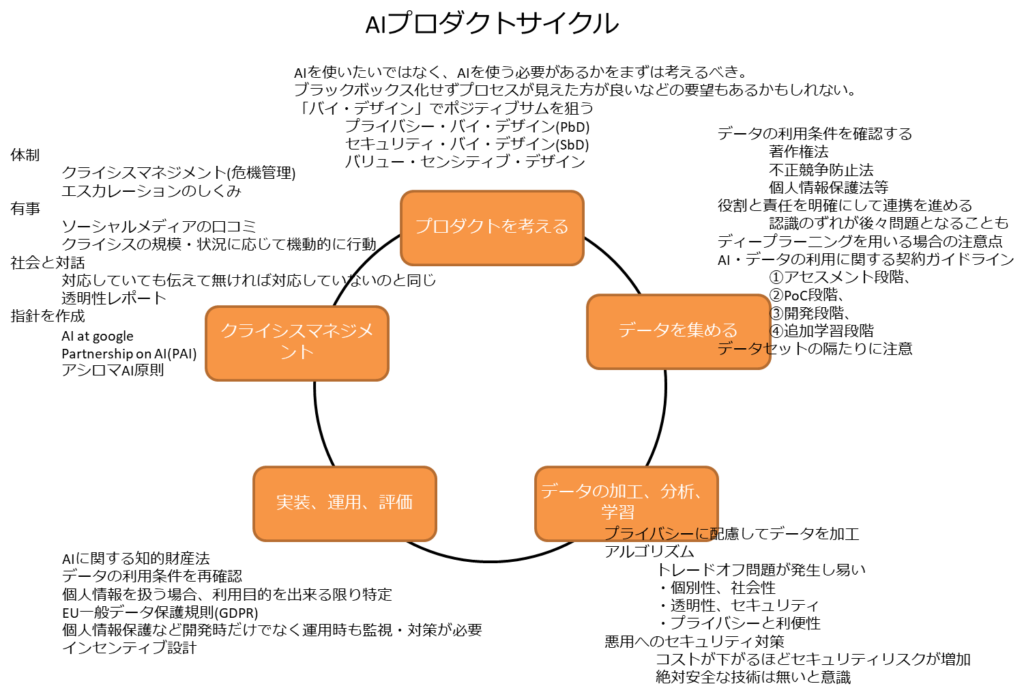
AIプロダクトを作る工程
以下のサイクルとなる。
- プロダクトを考える
- データを集める
- データの加工、分析、学習
- 実装、運用、評価
- クライシスマネジメント
プロダクトを考える
以下をまず考える必要あり
- なぜディープラーニングを取り入れた製品を利用したいのか
- ディープラーニングの導入自体が目的かしてしまっていないか
プライバシーに配慮した設計やプロセス(プライバシーバイデザイン)を意識することで信頼を獲得することが可能な場合がある。
同様にセキュリティバイデザイン、バリューセンシティブデザインなども考慮し、設計に埋め込む手法に注目が集まっている。
データを集める
気を付けなければならないデータ利用条件
- 著作権法
- 不正競争防止法
- 個人情報保護法
- 個別の契約
- その他
他企業、他業種と連携する場合、以下の懸念がある
- 双方の認識のズレ(期待の違い)
- プロジェクト管理の甘さ(作業遅延)
特にディープラーニング等を利用した開発では試行錯誤が多く、との点を踏まえたコミュニケーションと契約交渉が必要。
この性質はウォーターフォール型のソフトウェア開発とは親和性が低い。
経済産業省より、「AI・データの利用に関する契約ガイドライン」が公開。
https://www.meti.go.jp/press/2018/06/20180615001/20180615001.html
主に4つのフェーズがある。
- アセスメント
- PoC
- 開発
- 追加学習
また、データセットに偏りがある可能性がある。
この偏りが現実世界と同等ならば良いが、異なる場合は対策が必要となる。
データの加工、分析、学習
プライバシー
プライバシーリスクを低減するためにデータ加工が必要な場合がある。
経済産業省より「カメラ画像利用活用ガイドブック」が公開されている。
https://www.meti.go.jp/press/2017/03/20180330005/20180330005.html
アルゴリズム
トレードオフ問題が発生し易い
- 個別性、社会性
- 透明性、セキュリティ
- プライバシーと利便性
セキュリティ
開発者が想定していなかった使い方や悪用をされる可能性がある。
絶対安全な技術はないということを開発者は意識しておくことが必要。
事前策だけでなく、事後策も考える必要あり。
実装、運用、評価
知的財産
AIに関する知的財産法を意識する必要あり。
経済産業省より「AI・データの利用に関する契約ガイドライン」が公開されている。
https://www.meti.go.jp/press/2019/12/20191209001/20191209001.html
策定段階に於いての重点事項は以下となる。
- これからの時代に対応した人材・ビジネスを育てる
- 挑戦、創造活動を促す
- 新たな分野の仕組みをデザインする
学習用データの論点(日本国内)
- 情報解析を目的とする場合に限り、第三者の著作物が含まれていても一定の限度に於いて学習用データにできる。
- 上記は営利目的であっても適用される。(この点が諸外国よりも適用範囲が広い)
学習済みモデルの論点
- 著作権法の要件を満たせば、「プログラムの著作物」として保護される可能性あり。
- 特許法、不正競争防止法でも保護される可能性あり。
- 派生モデル、蒸留(ブラックボックス)モデルは議論継続
個人情報保護
データの利用条件を再確認する必要あり。
「開発時の利用目的以外で使っていないか?」にも気を付ける。
よって、個人情報を扱う場合、利用目的を出来る限り特定し、当初予定されていなかった用途で個人情報を扱う場合、事前の確認が必要。
EUでは最も厳しい部類になる、EU一般データ保護規則(GDPR)が施行されている。
これの背景にGAFA(Google、Apple、Facebook、Amazon)等の米国プラットフォーマーに対する市場寡占の対策の一つと考えられる。
予期しない振る舞い
システム開発後も対策や仕掛けが必要。
- システムが誰かの名誉棄損に繋がっているのを知りながら放置するのは違法
- 個人情報保護など開発時だけでなく運用時も監視・対策が必要
インセンティブ設計
AIベースのビズネスモデルや製品の市場化を進めるにはインセンティブが必要。
- OSSへのインセンティブ(知的財産)
- 投資家へインセンティブ(市場原動力)
- データ創造のインセンティブ(データデザイン人材の確保、維持)
- 学習データ、学習済みモデルのインセンティブ(モデルの流通)
広く社会一般を巻き込んで考えていく体制を作る必要がある。
クライシスマネジメント
体制
クライシスマネジメント(危機管理)が重要となる。
まずは体制作りが必要であり、いわゆる「火消し」や「復旧」ができる体制を維持する必要がある。
そして、利害関係者間での「エスカレーションのしくみ」を先んじて構築しなければならない。
定期的な防災訓練やそれに伴う危機管理マニュアル整備なども有事の際は効果的と言える。
有事対応
近年ではーシャルメディアの口コミが発端でクライシスに陥ることが増えてきている。
クライシスの規模・状況に応じて機動的に行動することがより重要となっている。
社会と対話
対応していても伝えて無ければ対応していないのと同じに見られる。
プライバシー、セキュリティなどの対応状況を共有/公開し、企業の透明性を担保し説明責任を果たす必要がある。
企業単位だけではなく、業界としても自治していくことが重要で、日本では一般社団法人セーフティーインターネット協会がサイトパトロールを行っている実績がある。
指針作成と議論継続
透明性レポートの作成や、社会との対話のため、各個人、企業、政府などが拠り所となる指針が必要。
Googleでは「AI at google」というAI技術開発原則を公開している。
2016年9月に設立したPartnership on AI(PAI)は以下を信条として掲げている。
- プライバシーとセキュリティの保護
- 当事者の利益の理解、尊重
- 社会的責任
- 頑健(がんけん)性、堅牢性の確保
- 人権の尊重
- 説明可能性
2017年1月カルフォルニア州アシロマにて開催されたBENEFICIAL AI 2017にてアシロマAI原則が公表されている。
本原則は以下3分類の計23の原則からなっている。
- 研究課題
- 倫理と価値
- 長期的な課題
プロダクトデザインへの反映
プロダクトは作ったら終わりではない。
そこから得た教訓を運用保守や次のプロダクト開発へと循環させていくサイクルが重要。


コメント
指針作成と議論継続という項目について、実際に PAI のサイトへ飛ぶと 8 つの条項があります!6 つに要約されたか、あるいはこの記事が掲載された当時から内容が変わったのでしょうか?
ここに書かれているのは要約です。
AI白書に記載された「民間における議論」がベースになっており、具体的な話に関しては特に追及はしていません。
実際のPAIの信条はご指摘の通り8項あり、当時からは変わっていないと認識しています。
1.技術が可能な限り多くの人々の役に立ち、活力を与えられるように努める。
2.一般の人々を啓発し、彼らの意見に耳を傾けるとともに、積極的に利害関係者の参画を促して、Pの取組事項についてフィードバックを求めたり、Pの活動に関する情報を提供したり、疑問に答えたりしていく。3.が倫理、社会、経済、法律に及ぼす影響について、オープンに研究し意見交換することを約束する。
3.が倫理、社会、経済、法律に及ぼす影響について、オープンに研究し意見交換することを約束する。
4.の研究開発成果は、幅広い利害関係者に使用を働きかけるとともに、当該関係者に対し説明可能である必要がある。
5.経済界の利害関係者と連携するとともに、代表者を招き入れ、に関連する懸念とが生み出す好機の双方がしっかり理解され、対処されるようにする。
6.技術がもたらす利益を最大化し、潜在的課題に対処するために、以下のことを行う。
a.個人のプライバシー保護とセキュリティ確保を図ること。
b.の進化により影響を受ける可能性のあるすべての関係者の利益を理解し尊重するよう努めること。
c.の研究や実用化を担うグループが、技術が社会全般に及ぼす潜在的影響について、社会的責任を負い、敏感であり、かつ直接的に携わり続けるようにすること。
d.の研究と技術が、堅牢で、確実で、信頼できるものであり、また安全制御のもと運用されるよう確保すること。
e.国際条約に違反したり、人権を侵害するような技術の開発や利用に反対するとともに、害を生じないような予防手段や技術を促進する。
7.AI技術を人々に説明するためには、AIのシステムがどのように運用されているかが、人々にとって理解可能・解釈可能であることが重要であると考える。
8.参加者全員がこれらの目標をより確実に達成できるように、AI科学者と技術者の間の、協力的で、信頼しあえる、オープンな文化を創造するよう努める。