
https://www.simulationroom999.com/blog/jdla-deep-learning-for-general-2020-1/

はじめに
ディープラーニングの研究分野の一つである、画像認識分野について記載する。
画像認識分野
基本的には以下課題がある。
- 位置課題
- 検出課題
AlexNet(アレックスネット)
2012年のイメージネット画像認識コンテスト(ILSVRC)に従来手法のサポートベクターマシンに代わって優勝。
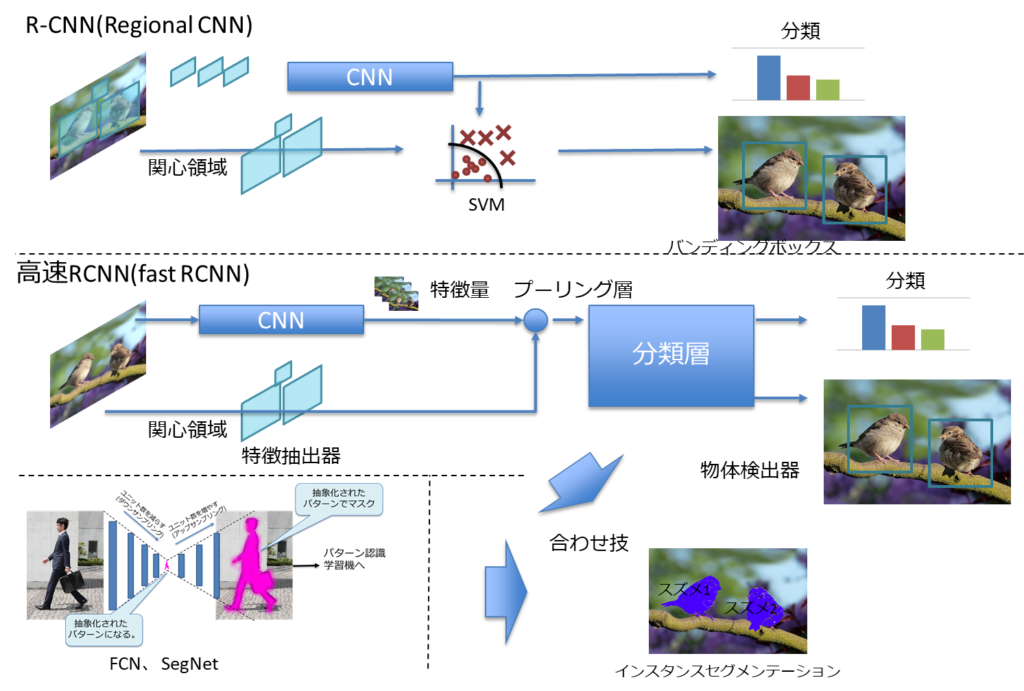
R-CNN(Regional CNN)
関心領域(Reqion of Interest:ROI)、所謂「どこ」の判別は、バンディングボックスという長方形で切り出す。
この長方形の4つの頂点を算出するのは回帰問題となる。
R-CNNでは、従来の画像分類手法を用いている。
CNNでは、入力画像中の位置情報も表現していると考えられる。
つまり、関心領域を切り出すための情報も含まれる。
これを利用したのが高速RCNN(fast RCNN)。
さらに改良を加えたものがfaster RCNN。
これらモデルにより、リアルタイムの関心領域の切り出しと認識ができるようになった。
発展形としてYOLO、SSDというモデルも提唱されている。
セマンティックセグメンテーション
セマンティックセグメンテーションはR-CNNの矩形領域を切り出すものと異なり、より詳細な領域分割を得るモデルとなる。
領域分割を詳細に行うために画素単位の指定が必要となる。
完全畳み込みネットワーク(Fully Comvolutional Network:FCN)はセマンティックセグメンテーションを実現するモデルとなる。
FCNとは全ての層が畳み込み層であるモデルとなる。
通常のCNNは出力層のユニット数が識別すべきカテゴリ数そのものであったことに対し、FCNは入力画像の画素数だけ出力層が必要となる。
出力層には縦画素数×横画素数×カテゴリ数の出力ニューロンが用意される。
CNNでは畳み込みのカーネル幅(受容野)だけ近傍の入力刺激を加えて計算するため、層を重ねると画像が荒くなる。このため、最終出力層に入力層と同じ画素数を得るために反対方向の解像度を細かくする工夫が必要となる。
これらの解決方法がアンサンプリング(unsampling)という方法で、入力側のプーリング層の情報を用いて詳細な解像度を得られる。
同様の仕組みがセグネット(Segnet)でも取り入られている。
インスタンスセグメンテーション
バウンディングボックスで切り出した領域内の物体識別を行っていたが、セマンティックセグメンテーションにより、各画素がどのカテゴリに属するかを求められる。
しかし、セマンティックセグメンテーションでは、複数の物体が同一のカテゴリに属すると扱われることも多い。
これに対し、物体ごとに認識されるものをインスタンスセグメンテーションと呼ぶ。
バンディングボックスとセマンティックセグメンテーションの双方を組み合わせることで実現できる可能性がある。
まとめ
- 物体を検出することと、物体を認識することは別
- しかし、「物体を認識」する過程で「物体を検出」している可能性もある
- 物体検出は矩形のバンディングボックスと画素単位のセマンティックセグメンテーションに分けられる。
- 双方をくみあわせることでインスタンスセグメンテーションが実現可能。


コメント