
https://www.simulationroom999.com/blog/jdla-deep-learning-for-general-2020-1/

はじめに
ディープラーニングの有名どころのモデルとしてCNNについて記載する。
CNN(畳み込みニューラルネットワーク)
画像データ
画像データは座標情報(縦横)の2次元に、色情報を加えたもので、数値情報としては3次元になる。
畳み込みニューラルネットワーク(Convolutional Neural Network:CNN)は座標情報の2次元データを入力するモデルとなる。
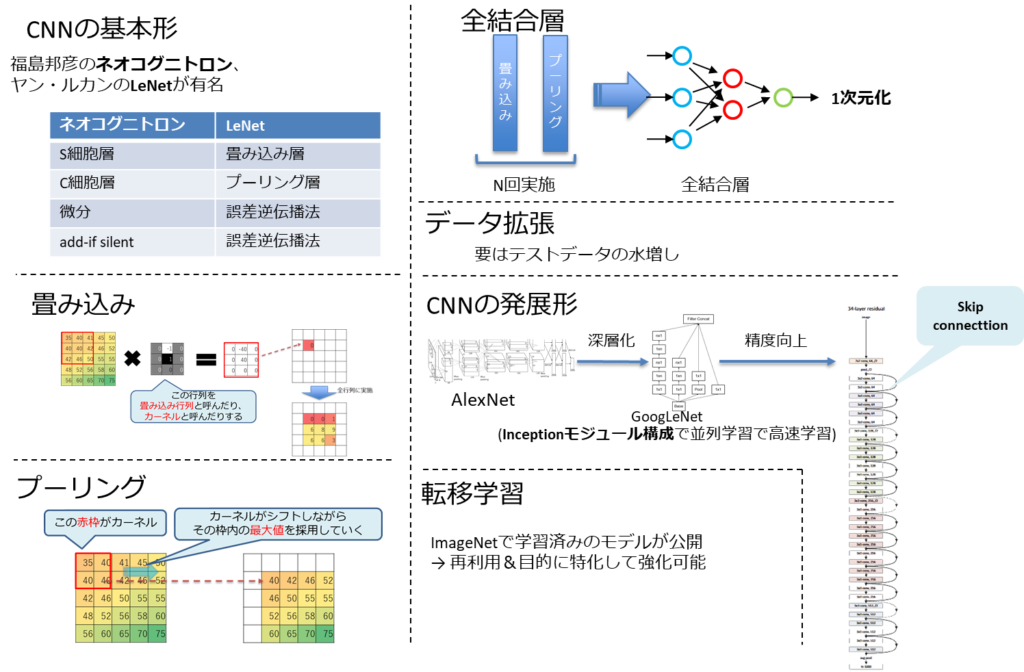
CNNの基本形
CNNは人間が持つ視覚野の神経細胞の2つの働きを模す。
- 単純型細胞(S細胞)
- 画像の特徴を検出
- 複雑型細胞(C細胞)
- 物体の位置が変動しても同一の物体と認識できる。
福島邦彦により上記2角細胞の性質を組み込んだネオコグニトロンが考案された。
多層構造であり、S細胞層とC細胞層が交互に4回組み込まれたモデルとなる。
ヤン・ルカンにより1998年にLeNetというCNNモデルが発表された。
畳み込み層とプーリング層(サブサンプリング層)の2層を交互に複数回組み込んだモデルとなる。
ネオコグニトロンとLeNetの違いは学習方法にある。
- ネオコグニトロン → add-if silent
- LeNet → 誤差逆伝播法
畳み込み
畳み込み(Convolution)とは、カーネルという画像よりも小さいフィルタを用いた画像特徴抽出のことを指す。
フィルタを画像の左上から順番に重ね合わせていき、画像とフィルタの値をそれぞれ掛け合わせたものの総和をとった値を求めていく処理となり、特徴マップが生成される。このフィルタがニューラルネットワークの重みになる。
人間が持つ移動不変性の能力を獲得した「位置のズレ」に強いモデルとなる。
プーリング
プーリングは、画像サイズを小さくするために決められた演算を行うだけのものである。
ダウンサンプリング、サブサンプリングとも呼ばれる。
主に以下2種類がある。
- Maxプーリング
- 画像の最大値を抽出する
- avgプーリング
- 画像の平均値を抽出する
全結合層
CNNは2次元データを扱うが、最終的な出力の形は1次元となる。
そのため、全結合層を使用する。
しかし、最近は1つの特徴マップに1つのクラスを対応させるGlobal Average Pooling(GAP)が主流になっている。
Global Average Poolingは各チャンネル(RGB)の画素平均をn次元のベクトルに落とし込む手法である。
データ拡張
画像認識には以下の課題が存在する。
- 同一の物体でも角度が異なると、画像としては別物
- 同一の物体でも距離が異なると、画像としては別物
- 同一の物体でも光源が異なると、画像としては別物
これらをすべて学習するためにデータ収集することは現実的ではない。
よって、データ拡張(data augmentation)という手法がとられる。
端的に言うとデータの「水増し」である。
具体的には以下のような処理を手元のデータに実施して水増しする。
- 上下左右にずらす
- 上下左右を反転
- 拡大、縮小
- 回転
- 斜めにゆがめる
- 一部を切り取る
- コントラストを変える
CNNの発展形
2012年のILSVRCで圧倒的勝利を修めたAlexNetは
(畳み込み→プーリング)×2→畳み込み×3→プーリング→全結合層×3
であった。
VGGやGoogLeNetはそれ以上の層で構成しており、AlexNetの記録を超えて行った。
しかし、層を増やすと計算量が膨大になるため、小さなサイズの畳み込みフィルターを差し込んで次元(計算量)を削減する工夫が取られた。
また、GoogleNetではInceptionモジュールを組み合わせた方式と取っていた。
いくつかの工夫により層を深くしても効率的に学習できたが、超深層になると性能が落ちるという問題にも直面した。
誤差が逆伝播しにくくなり、学習がうまくいかなくなる。
これに対し、Skip connectionと呼ばれる「層を飛び越えた結合」を加える手法が考え出された。
この手法を導入したネットワークをResNetと呼ぶ。
これにより、以下の効果により学習がうまく行くようになった。
- 層が深くなっても層を飛び越える部分は伝播し易くなる。
- 様々な形のネットワークのアンサンブル学習になる。
転移学習
転移学習とは学習済みのネットワークを利用して新しいタスクの識別に活用することを指す。
ディープニューラルネットワークに於いて重要なのは最適化されたネットワークの重みであり、学習そのものはその重みを得るための手段に過ぎない。学習済みのネットワークがあるならばそれを流用した方が容易且つ確実である。
先述のモデルはImageNetで学習済みのモデルが公開されており、誰でも利用できるようになっている。
これらに新たな層を追加し、ファインチューニングすることで自分の目的とした高性能なネットワークを得ることができる。
まとめ
- 画像による物体認識は長年の課題の一つであり、それが解決しつつある。
- しかし、それには膨大な学習が必要となるが、公開されているネットワークも多い。
- 公開ネットワークに層を追加しファインチューニングすることで手早く高性能なネットワークが獲得できる。


コメント