
MATLAB、Python、Scilab、Julia比較ページはこちら
https://www.simulationroom999.com/blog/comparison-of-matlab-python-scilab/

はじめに

の、
MATLAB,Python,Scilab,Julia比較 第4章 その98【モーメンタム⑧】
を書き直したもの。
ニューラルネットワークの最適化アルゴリズムについて。
モーメンタムをプログラムとして実装する。
今回はPythonで実現。
モーメンタムのプログラムフロー【再掲】
まずは、プログラムフローを再掲。
- シグモイド関数の定義
- シグモイド関数の導関数の定義
- データの準備
- ネットワークの構築
- 重みとバイアスの初期化
- モーメンタム項の初期化
- 学習(4000エポック)
- 順伝播
- 誤差計算(平均二乗誤差)
- 逆伝播
- パラメータの更新(モーメンタム)
- 決定境界線の表示
今回は、Pythonで実現する。
Pythonコード
Pythonコードは以下。
import numpy as np
import matplotlib.pyplot as plt
# シグモイド関数の定義
def sigmoid(x):
return 1 / (1 + np.exp(-x))
# シグモイド関数の導関数の定義
def sigmoid_derivative(x):
return sigmoid(x) * (1 - sigmoid(x))
# データの準備
X = np.array([[0, 0], [0, 1], [1, 0], [1, 1]]) # 入力データ
y = np.array([[0], [1], [1], [0]]) # 出力データ
# ネットワークの構築
hidden_size = 4 # 隠れ層のユニット数
output_size = 1 # 出力層のユニット数
learning_rate = 0.5 # 学習率
momentum = 0.9 # モーメンタム
input_size = X.shape[1]
W1 = np.random.randn(input_size, hidden_size) # 入力層から隠れ層への重み行列
b1 = np.random.randn(1, hidden_size) # 隠れ層のバイアス項
W2 = np.random.randn(hidden_size, output_size) # 隠れ層から出力層への重み行列
b2 = np.random.randn(1, output_size) # 出力層のバイアス項
# モーメンタム項の初期化
vW1 = np.zeros_like(W1)
vb1 = np.zeros_like(b1)
vW2 = np.zeros_like(W2)
vb2 = np.zeros_like(b2)
# 学習
epochs = 4000 # エポック数
errors = np.zeros(epochs) # エポックごとの誤差を保存する配列
for epoch in range(epochs):
# 順伝播
Z1 = np.dot(X, W1) + b1 # 隠れ層の入力
A1 = sigmoid(Z1) # 隠れ層の出力
Z2 = np.dot(A1, W2) + b2 # 出力層の入力
A2 = sigmoid(Z2) # 出力層の出力
# 誤差計算(平均二乗誤差)
error = np.mean((A2 - y) ** 2)
errors[epoch] = error
# 逆伝播
delta2 = (A2 - y) * sigmoid_derivative(Z2)
delta1 = np.dot(delta2, W2.T) * sigmoid_derivative(Z1)
grad_W2 = np.dot(A1.T, delta2)
grad_b2 = np.sum(delta2, axis=0)
grad_W1 = np.dot(X.T, delta1)
grad_b1 = np.sum(delta1, axis=0)
# パラメータの更新
vW1 = momentum * vW1 - learning_rate * grad_W1
vb1 = momentum * vb1 - learning_rate * grad_b1
vW2 = momentum * vW2 - learning_rate * grad_W2
vb2 = momentum * vb2 - learning_rate * grad_b2
W1 += vW1
b1 += vb1
W2 += vW2
b2 += vb2
# 決定境界線の表示
h = 0.01 # メッシュの間隔
x1, x2 = np.meshgrid(np.arange(np.min(X[:,0])-0.5, np.max(X[:,0])+0.5, h),
np.arange(np.min(X[:,1])-0.5, np.max(X[:,1])+0.5, h))
X_mesh = np.c_[x1.ravel(), x2.ravel()]
hidden_layer_mesh = sigmoid(np.dot(X_mesh, W1) + b1)
output_layer_mesh = sigmoid(np.dot(hidden_layer_mesh, W2) + b2)
y_mesh = np.round(output_layer_mesh) # 出力を0または1に丸める
decision_mesh = y_mesh.reshape(x1.shape) # 分類結果のメッシュを元のグリッドサイズに変形する
colormap = ['#CCFFCC','#FFCCCC'] # 各領域の色を指定する
plt.contourf(x1, x2, decision_mesh, levels=1, colors=colormap) # カラーマップを適用する
plt.scatter(X[y.flatten() == 1, 0], X[y.flatten() == 1, 1], color='r', marker='o', label='Class 1') # クラス1のデータ点を赤でプロット
plt.scatter(X[y.flatten() == 0, 0], X[y.flatten() == 0, 1], color='g', marker='o', label='Class 0') # クラス0のデータ点を緑でプロット
plt.xlabel('X1')
plt.ylabel('X2')
plt.title('XOR Classification')
plt.legend(loc='best')
plt.grid()
plt.show()
plt.plot(errors[0:1000])
plt.show()処理結果
処理結果は以下。
分類のパターンとしては大きく2パターンあるので、それぞれを分類と誤差関数の推移を掲載。
パターン1
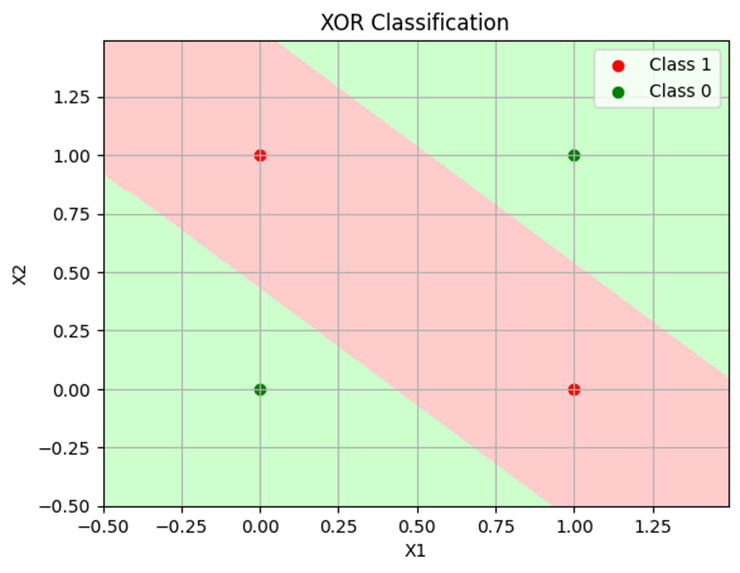
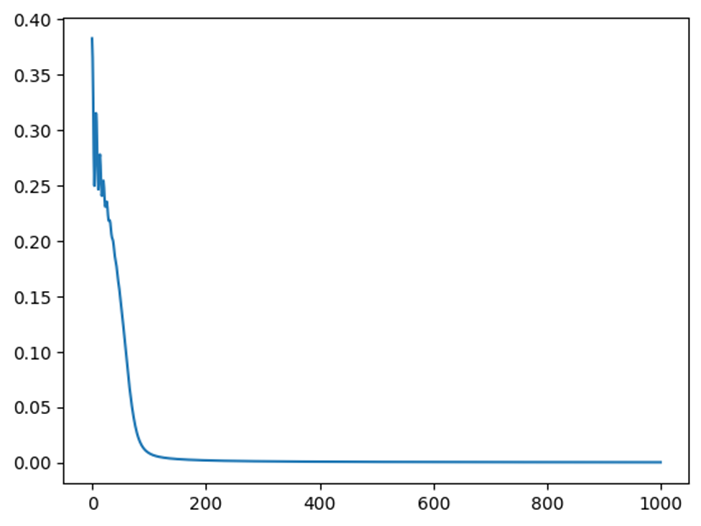
パターン2
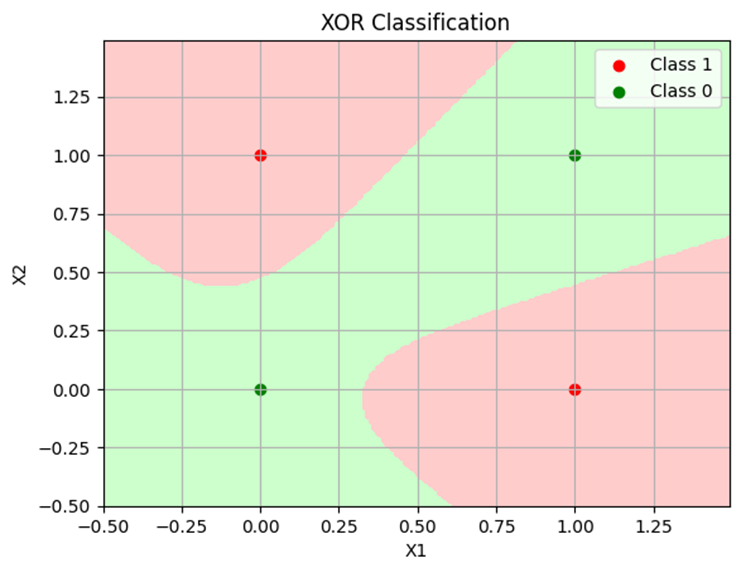
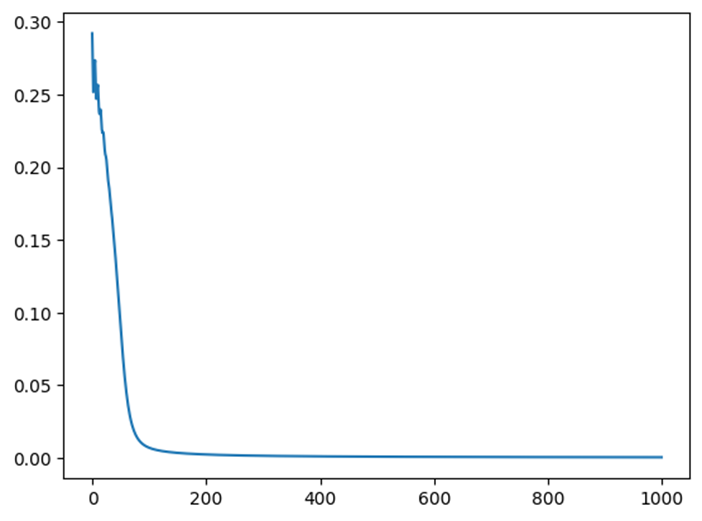
まとめ
- 最適化アルゴリズム モーメンタムを用いて分類の学習をPythonで実現。
- 問題無く動作。
- 学習の収束が通常の勾配降下法よりも比較的早い。
MATLAB、Python、Scilab、Julia比較ページはこちら
Pythonで動かして学ぶ!あたらしい線形代数の教科書

Amazon.co.jp: Pythonで動かして学ぶ!あたらしい線形代数の教科書 eBook : かくあき: Kindleストア
Amazon.co.jp: Pythonで動かして学ぶ!あたらしい線形代数の教科書 eBook : かくあき: Kindleストア
amzn.to
ゼロから作るDeep Learning ―Pythonで学ぶディープラーニングの理論と実装

ゼロから作るDeep Learning ―Pythonで学ぶディープラーニングの理論と実装 | 斎藤 康毅 |本 | 通販 | Amazon
Amazonで斎藤 康毅のゼロから作るDeep Learning ―Pythonで学ぶディープラーニングの理論と実装。アマゾンならポイント還元本が多数。斎藤 康毅作品ほか、お急ぎ便対象商品は当日お届けも可能。またゼロから作るDeep Lea...
amzn.to
ゼロからはじめるPID制御

ゼロからはじめるPID制御 | 熊谷 英樹 |本 | 通販 | Amazon
Amazonで熊谷 英樹のゼロからはじめるPID制御。アマゾンならポイント還元本が多数。熊谷 英樹作品ほか、お急ぎ便対象商品は当日お届けも可能。またゼロからはじめるPID制御もアマゾン配送商品なら通常配送無料。
amzn.to
OpenCVによる画像処理入門

OpenCVによる画像処理入門 改訂第3版 (KS情報科学専門書) | 小枝 正直, 上田 悦子, 中村 恭之 |本 | 通販 | Amazon
Amazonで小枝 正直, 上田 悦子, 中村 恭之のOpenCVによる画像処理入門 改訂第3版 (KS情報科学専門書)。アマゾンならポイント還元本が多数。小枝 正直, 上田 悦子, 中村 恭之作品ほか、お急ぎ便対象商品は当日お届けも可能。...
amzn.to
恋する統計学[回帰分析入門(多変量解析1)] 恋する統計学[記述統計入門]

恋する統計学[回帰分析入門(多変量解析1)] 恋する統計学[記述統計入門] | 金城俊哉 | 数学 | Kindleストア | Amazon
Amazonで金城俊哉の恋する統計学 恋する統計学。アマゾンならポイント還元本が多数。一度購入いただいた電子書籍は、KindleおよびFire端末、スマートフォンやタブレットなど、様々な端末でもお楽しみいただけます。
amzn.to
Pythonによる制御工学入門

Amazon.co.jp
amzn.to
理工系のための数学入門 ―微分方程式・ラプラス変換・フーリエ解析

Amazon.co.jp
amzn.to


コメント